Who Owns Your Company Memory?
Anyone who has ever had to replace a central system knows the problem: the data is rarely the hardest part. The hard parts are the exceptions, dependencies, approvals, interfaces, and routines that have accumulated over years. It feels as if you were replacing both the wiring and the heating system of a building at the same time.
Practical test for this essay
Three templates for a conversation with an AI: clarify the goal, check contradictions, test whether the work can be delegated. You do not get a finished strategy or a tool recommendation.
Open the templatesTool Radar
A due-diligence map for vendors and architecture building blocks around agentic company memory.
Download PDFAI agents add a new layer to that problem. And with it, the danger of becoming even more tightly bound to a specific vendor than with previous systems.
Agents can do more than find documents or answer questions. They do concrete work, they are embedded in teams and workflows, and while doing that they learn how a company works: which sources matter, which exceptions count, which relationships exist between customers, cases, and contracts, which decisions are accepted, and which feedback signals quality.
If that memory sits with the vendor, a future switch is no longer a simple migration.
It becomes reconstruction work. You have to transfer an organizational working memory. Or rebuild it from zero.
Because an agent does not only remember facts. It also remembers work in motion.
With every request, every correction, every tool call, and every approval, a picture emerges of how people actually work. Not how the process looks on the PowerPoint slide. How it runs at 9:17 on a normal Tuesday morning, when Legal deletes a phrase, Sales makes an exception, Controlling trusts one table more than another, and the senior person in the team says, “Not like that, but close.”
That is where working memory becomes strategic.
Whoever controls that layer controls more than access to information. They control a non-trivial part of the operating logic.
Stay up to date
Get notified when I publish something new, and unsubscribe at any time.
Continue working: The web version comes with two practical companion assets: the dekodiert Werkbank helps you test your own agentic-memory architecture. The Agentic Memory Vendor Radar maps vendors and building blocks by memory layer, public-source status, and DE/EU due-diligence questions. The radar is also available there as a PDF.
The practical mistake begins when companies still treat this layer with a single word: memory. I see that in the current discussion on LinkedIn, in conversations with colleagues in the industry, and with clients.
Many still mean RAG when they say memory: making documents available inside AI chats. That is a sensible starting point, but already too narrow. Agentic work needs different forms of memory: references, document structure, relational data, repeated decisions, and feedback. It works with databases, tables, and documents where semantic structure can be just as important as the content of individual passages. RAG may find you a similar clause in the contract with your most important customer on page 4. The exception on page 9 of the appendix may be semantically so different that it does not find it.
An agent that only works with the main clause, but never sees the exception, will confidently produce expensive nonsense.
Workflows like that, whether agentic or human, need different knowledge architectures. A search index does not solve relationship logic. A chat history does not replace an auditable approval. A knowledge graph does not automatically explain which feedback signals quality. Semantic search finds similarity, not meaning in document structure.
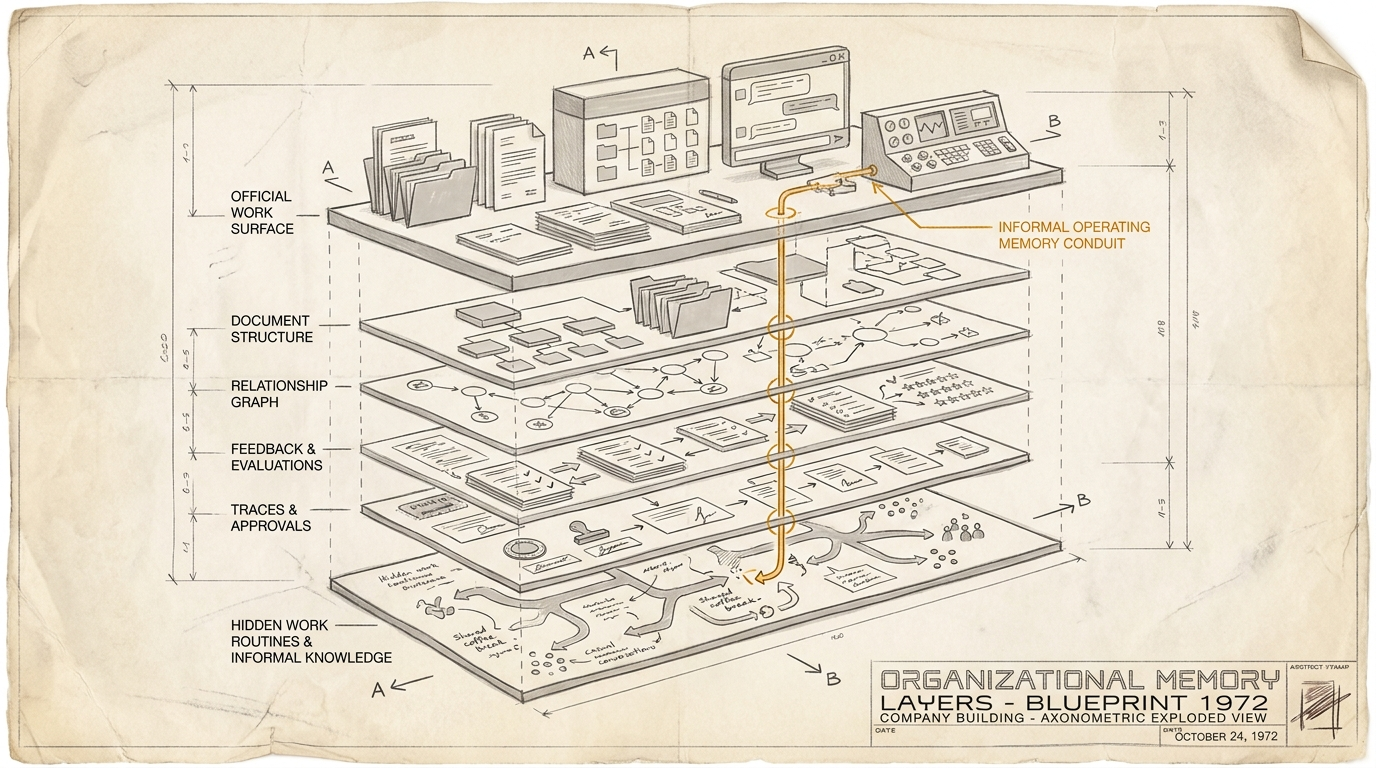
That is why this architecture has to be separated into its constituent parts before anyone decides what to buy. At this point, the four most important layers look like this.
1. Finding documents: retrieval
This is the simplest and best-known form.
An agent is supposed to find relevant documents: policies, contracts, offers, minutes, specifications, emails, knowledge articles. For that you need search indexes, embeddings, access rights, updates, source references, and clean boundaries between teams.
That matters. But it only answers one question: Where does something stand?
Many companies confuse that with company memory. That is convenient. Too convenient.
Retrieval can say: here is the document that probably fits. It does not automatically understand which clause has which effect in which part of the contract. It does not necessarily know whether an old exception still applies. It cannot, by itself, explain why two documents contradict each other or which rule takes precedence in a conflict.
Retrieval is a librarian. Not an operating architect.
2. Understanding documents: structure and meaning
The second layer is harder.
Many company documents are not just text. They have structure: sections, appendices, clauses, versions, tables, validity periods, responsibilities, exceptions, cross-references.
A contract is not just a long text. A policy is not just a PDF. A technical manual is not just a search hit. A pitch deck is not just slide content. The meaning often sits in the structure.
That needs a different architecture than pure retrieval. You need parsing, segmentation, document models, versioning, validation, and sometimes domain-specific extraction. Otherwise the agent may find the right document and still understand the wrong layer.
That is the difference between “find me the policy” and “tell me which exception really applies in this case.”
If you only build retrieval, you get quick references. Not automatically reliable document understanding.
For pure retrieval, documents often have to be split into chunks and translated into mathematically comparable vectors. For semantic structure, a document sometimes must not be split in exactly that way. That alone shows how different the architecture can be.
3. Tables and relationships: the operating network
The third layer sits in tables, databases, and relationships.
Customers, products, contracts, tickets, cases, campaigns, machines, spare parts, suppliers, accounts, permissions. Company reality is not just documented. It is relational.
An agent that is supposed to support real work must know more than the fact that a contract exists. It has to know which customer, product, case, region, risk status, and approval are connected to it.
That is not the same as document RAG.
This is about data models, entity resolution, knowledge graphs, data quality, permissions, and clean semantics. If two systems spell the same customer differently, that is not a prompt problem. If an agent draws the wrong relationship, the result is not just bad text. It can become a wrong decision.
Many company agents will end up exactly here, because the real work is not writing answers. It is connecting cases, data, documents, and decisions.
4. Workflows: decisions, exceptions, routines
The fourth layer is the most dangerous one.
It does not emerge in documents or tables, but in repeated work.
Which answer does a team accept? Which exception is always escalated? Which phrase does Legal delete every time? Which source does the business unit really trust? Which customer group gets special treatment? Which senior person gives informal approval even though they do not appear in the process?
That is lived operating intelligence.
Agents can collect this layer systematically for the first time: through prompts, feedback, session transcripts, tool calls, corrections, evals, approvals, and memory stores. That is exactly where it becomes strategic.
Because this layer is valuable. And poorly portable.
If it sits with the vendor, what sits there is not just context. It is part of the way the company works.
Vendor switching becomes reconstruction
This is where the comparison to migrating away from SAP becomes useful. Maybe a little mean.
Honestly: a SAP migration is awful, but at least it has a recognizable task. Data, processes, interfaces, and permissions have to be moved into a new landscape. You can plan it badly. You can underestimate it. You can ruin yourself on it. Happens. The probability is clearly above zero that a SAP migration is more career killer than career booster.
But at least you roughly know what has to be migrated. You know what you are facing.
With agentic memory, it gets harder. The loss does not sit only in files or databases. It sits in condensations.
An agent has learned over months, maybe years, which source matters in which context. Which exception is no longer a special case. Which approval is really needed in practice. Which wording does not work for which customer. Which hints senior people give when an output is almost right, but not good enough.
When you switch vendors, you may get raw material out: logs, transcripts, embeddings, exported memories, prompts, configuration files, maybe even evals. And even that is not guaranteed today. Hardly any vendor talks clearly about how you leave again.
Even if they do, raw material is not the same as working ability.
An export can be technically complete and operationally half useless. Because the semantics are missing. Because feedback is not typed cleanly. Because a memory entry is no longer understandable without its context. Because evals are tied to a specific harness. Because tool calls have no meaning without the target system. Because no one documented which learned routine was critical and which was only comfort.
That is the difference between migration and reconstruction.
Migration means: we move a known system.
Reconstruction means: we try to find out what the system had learned about us.
That is why this debate is more practical than it sounds at first. Not because every vendor is evil. Because successful agents inevitably sit close to repeated work. The more useful they become, the more operating experience accumulates inside them.
The next question is not vendor. It is architecture.
Here is the central mistake in many AI programs.
They talk about “the agent” as if there were one architecture that can do everything.
There is not.
A search index does not solve document understanding. A document parser does not solve relational data problems. A knowledge graph does not solve informal approval routines. Chat memory does not solve auditability. An eval harness does not solve data quality. And a multimodal model does not answer the question of who owns its interpretations later.
That is not an academic distinction. It is the difference between a useful pilot and an expensive dependency.
The first question before every agent job should be:
What kind of memory does this workflow actually need?
A policy assistant mainly needs document structure. A claims process needs relationships between contract, claim, exception, and decision. Marketing and consulting need briefing logic, approvals, brand patterns, and learned client preferences. Technical service needs manuals, spare parts, machine history, and error patterns.
If you do not separate that, you buy a nice demo. And later wonder why it does not hold in operations.
The market solves layers, not the whole thing
This is the uncomfortable part.
No vendor has fully solved this problem yet.
Microsoft, Google, Glean, Salesforce, ServiceNow, Atlassian, SAP, Workday, and Notion sit close to existing work surfaces and systems of truth. That is powerful, because real work happens there. It is also risky, because context, habit, and default pull emerge in exactly those places.
Other vendors solve more controllable building blocks: deepset, Elastic, Weaviate, Qdrant, Neo4j, Graphwise, Langfuse, Braintrust, or Arize Phoenix. They offer more control over retrieval, graphs, evals, or traces. The price is more architecture and operating competence.
Then there is the new memory layer: Zep, Mem0, Letta, Anthropic Managed Agents, and similar approaches. That is where you can see where this is going: persistent agents, graph memory, traces, evals, memory reorganization. Interesting. But not automatically procurement-ready for German and European companies.
The market map therefore does not show a winner.
It shows layers.
And that is the point: a vendor can be strong in one layer and weak in another. A good model does not make a good company memory. A good admin console does not make an exit architecture. A convincing demo memory says nothing about whether evals, traces, and work routines will still be understandable, deletable, and portable in two years.
For procurement and management, this is uncomfortable. The old SaaS question was easier: server location, DPA, role model, export function, price.
All of that still matters.
It is no longer enough.
The new question is:
Which parts of our work does this system learn, in what form, with which owner, and with which switching option?
If a vendor cannot answer that precisely, it is not a detail for later. It is the core of the decision.
Do not build everything yourself. But know what you own.
This does not mean companies now have to build everything themselves.
That would be the next bad idea. Hardly any mid-sized company should suddenly operate its own memory infrastructure, its own evals, its own graphs, and its own agent runtimes. Many enterprise teams should not do that either unless they have to.
But companies need to know which layers they buy and which layers they want to own.
Operations can be outsourced. Responsibility cannot.
Convenience can sit with the vendor. Critical company memory needs at least mirroring, export, audit, and clear ownership rules.
Otherwise you only notice at the point of switching that you did not just use a tool. You taught a tool how your organization works.
First the question was who had the best model. Then who could connect the best tools. Next it will be who holds the memory.
Memory becomes a strategic layer.
Not because memory makes things nicely personalized. Because context, routine, evaluation, and exit costs meet there.
In Germany, this gets concrete quickly
For German and European companies, this is not just a platform question.
As soon as agents store work routines, data protection, co-determination, audit, and governance questions appear.
Data protection asks which personal data ends up in memory, logs, feedback, and agent traces. Article 35 GDPR makes data protection impact assessments relevant where new technologies are likely to create high risks for rights and freedoms. Article 22 GDPR is narrower and does not apply to every agent. But once automated decisions have legal or similarly significant effects, the line gets hard.
Co-determination asks whether work behavior becomes visible, measurable, or steerable. Section 87(1)(6) of the German Works Constitution Act is the dry German anchor here: the works council has co-determination rights for technical systems intended to monitor employee behavior or performance.
An agent system with logs, memory, productivity metrics, and individual feedback traces can enter that zone very quickly.
The EU AI Act adds another layer. Article 4 requires AI literacy for providers and deployers. Article 14 describes human oversight for high-risk systems. Article 26 formulates obligations for deployers of high-risk systems. Not every company agent is automatically high-risk. But the direction is clear: anyone using AI productively has to take people, oversight, and use context seriously.
That is not a reason to do nothing.
It is a reason not to leave the architecture to the most convenient vendor default.
What must be clarified before the next pilot
The wrong question is:
Which vendor has the best agent memory?
The better question is:
What kind of memory may sit where in our organization?
Before the next agent pilot, four things should be clarified.
1. Classify the workflow
Is the workflow mainly about retrieval, document understanding, relational data, work routines, multimodal perception, or orchestration?
2. Define ownership
Which parts of this memory must belong to the organization, regardless of model or tool provider?
3. Simulate the exit
After twelve months, what would really be lost in a vendor switch: files, prompts, evals, feedback, traces, work routines, relationships, or client preferences?
4. Pull governance before the pilot
Which data, logs, feedback traces, and evaluation patterns touch data protection, works council, audit, or compliance?
That is less convenient than “let us just test an agent.”
But that is exactly where lock-in emerges: not when the contract is signed, but when a successful pilot turns into habit.
Two tools for the next decision
To make these questions less abstract, I prepared two companion pieces.
The Agentic Memory Architecture Werkbank helps you break down a concrete workflow: which memory layers it needs, which risks emerge, and what must remain exportable.
The Agentic Memory Vendor Radar for DE/EU maps vendors and building blocks along those layers. Not as a leaderboard. As a market map: who sits close to the work surface? Who offers controllable infrastructure? Where do traces, graphs, evals, or memory stores emerge? And which DE/EU questions need to be on the table before a pilot?
If all you want to know is “which vendor is good,” you will not be happy there.
If you want to understand which dependency you are building, it may help.
The real test
The next vendor decision should not run only through IT, Legal, and Procurement. It needs a memory architecture question.
It is this:
If we had to switch this vendor in two years, what could we export, and what would we have to learn again as an organization?
If the answer only lists files, user accounts, and contract clauses, it is incomplete.
The hardest lock-in does not emerge where data is stored. It emerges where a system has learned how work really runs inside an organization.
The old lock-in sat in systems you could at least map.
The new one sits in company memory.
Practical test for this essay
Three templates for a conversation with an AI: clarify the goal, check contradictions, test whether the work can be delegated. You do not get a finished strategy or a tool recommendation.
Open the templatesGo deeper
Three follow-up pieces if you want to take the argument further.
The New Lock-In Lives in Memory
APIs can be swapped. Habits, approvals, and learned context are much harder to move. Why the next major AI lock-in may cut deeper than classic …
Why AI Tools Fail – And Where the Real Lever Is
The bottleneck isn't the software. It's the knowledge that only exists in people's heads. Why institutional context is the real lever – and why most …
The Wrong Black Box Problem
Often the biggest mystery is not the model but the company itself: rules are missing, knowledge lives in people’s heads, and decisions are described …