Wem gehört euer Unternehmensgedächtnis?
Wer schon einmal ein zentrales System wechseln musste, kennt das Problem: Die Daten sind selten der schwierigste Teil. Schwer sind die Ausnahmen, Abhängigkeiten, Freigaben, Schnittstellen und Routinen, die sich über Jahre angesammelt haben. Es fühlt sich an, als würde man gleichzeitig sowohl die Verkabelung, als auch die gesamte Heizung in einem Gebäude tauschen.
Praktischer Test zum Essay
Drei Vorlagen für ein Gespräch mit einer KI: Ziel klären, Widersprüche prüfen, Delegierbarkeit testen. Du bekommst keine fertige Strategie und keine Tool-Empfehlung.
Vorlagen öffnenTool Radar
Eine Due-Diligence-Landkarte für Anbieter und Architekturbausteine rund um agentisches Unternehmensgedächtnis.
PDF herunterladenBei AI-Agenten kommt nun eine neue Schicht hinzu. Und damit die Gefahr, sich noch stärker an einen bestimmten Anbieter zu binden als bei bisherigen Systemen.
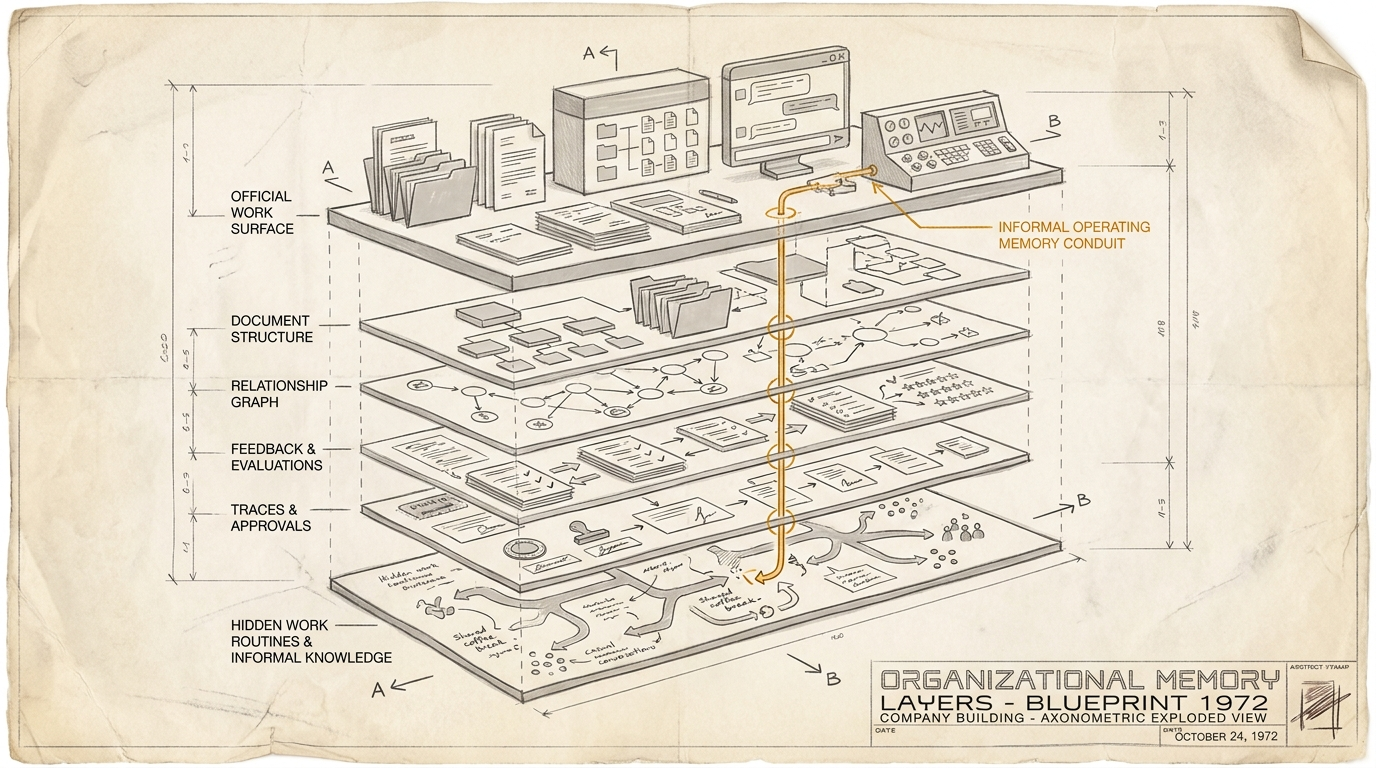
Agenten können nicht nur Dokumente finden oder Fragen beantworten. Sie leisten konkrete Arbeit, sind in Teams und Workflows eingebunden und sie lernen dabei, wie ein Unternehmen arbeitet: welche Quellen zählen, welche Ausnahmen wichtig sind, welche Beziehungen zwischen Kunden, Fällen und Verträgen bestehen, welche Entscheidungen akzeptiert werden und welche Rückmeldungen Qualität bedeuten.
Wenn dieses Gedächtnis beim Anbieter liegt, ist ein späterer Wechsel nicht mehr nur eine "einfache" Migration.
Ein solcher Wechsel wird Rekonstruktionsarbeit. Man muss ein organisationales Arbeitsgedächtnis transferieren. Oder von null neu aufbauen.
Denn ein Agent merkt sich nicht nur Fakten. Er merkt sich eben auch die Arbeit "im Vollzug".
Mit jeder Anfrage, jeder Korrektur, jedem Toolaufruf und jeder Freigabe entsteht ein Bild davon, wie Menschen tatsächlich arbeiten. Nicht wie der Prozess auf der PowerPoint-Folie aussieht. Sondern wie er morgens an einem ganz normalen Dienstag um 9:17 Uhr wirklich läuft, wenn Legal eine Formulierung streicht, der Vertrieb eine Ausnahme macht, das Controlling einer bestimmten Tabelle mehr vertraut als einer anderen und der Senior im Team sagt: „So nicht, aber fast.“
Genau dort wird das Arbeitsgedächtnis strategisch.
Wer diese Schicht kontrolliert, kontrolliert nicht nur Zugriff auf Informationen. Er kontrolliert einen nicht zu unterschätzenden Teil der Betriebslogik.
Bleib auf dem Laufenden
Erhalte eine Nachricht, wenn ein neuer Essay erscheint. Jederzeit abbestellbar.
Weiterarbeiten: Zur Webfassung gehören zwei praktische Anschlussstücke: Die dekodiert Werkbank hilft euch, die eigene Agentic-Memory-Architektur zu prüfen. Der Agentic Memory Vendor Radar ordnet Anbieter und Bausteine nach Memory-Schichten, öffentlichem Quellenstand und DE/EU-Prüffragen. Den Radar gibt es dort auch als PDF.
Der praktische Fehler beginnt, wenn Unternehmen diese Schicht trotzdem mit einem einzigen Wort behandeln: Memory. Und genau das sehe ich in der aktuellen Diskussion auf LinkedIn und in Gesprächen mit Kollegen in der Branche und mit Kunden.
Viele verstehen darunter vor allem noch RAG: Dokumente in KI-Chats verfügbar machen. Das ist ein sinnvoller Einstieg, aber heute bereits zu eng. Agentische Arbeit greift auf verschiedene Formen von Gedächtnis zu: Fundstellen, Dokumentstruktur, relationale Daten, wiederholte Entscheidungen und Feedback. Sie arbeitet mit Datenbanken, Tabellen und Dokumenten, in denen die semantische Struktur ebenso wichtig ist wie der Inhalt einzelner Abschnitte. RAG kann dir eine vergleichbare Stelle im Vertrag mit deinem wichtigsten Kunden auf Seite 4 finden. Die Ausnahmeregelung auf Seite 9 des Anhangs ist semantisch aber so anders, dass es sie oft nicht findet.
Ein Agent, der daher also nur mit der eigentlichen Klausel arbeitet, die Ausnahme aber nie sieht (und somit nicht kennt), wird mit fester Überzeugung teuren Schwachsinn produzieren.
Derartige Arbeitsabläufe (egal ob agentisch oder menschlich) brauchen daher unterschiedliche Wissensarchitekturen. Ein Suchindex löst keine Beziehungslogik. Ein Chatverlauf ersetzt keine auditierbare Freigabe. Ein Knowledge Graph erklärt nicht automatisch, welche Rückmeldung Qualität bedeutet. Und semantische Suche findet Ähnlichkeiten, nicht Bedeutung in der Dokumentstruktur.
Deshalb muss man diese Architektur in ihre konstituierenden Bestandteile auftrennen, bevor man darüber nachdenkt, was man einkaufen sollte. Die vier wichtigsten Schichten sehen, zum jetzigen Zeitpunkt, so aus.
1. Dokumente finden: Retrieval
Das ist die einfachste und bekannteste Form.
Ein Agent soll relevante Dokumente finden: Richtlinien, Verträge, Angebote, Protokolle, Spezifikationen, Mails, Wissensartikel. Dafür braucht man Suchindexe, Embeddings, Zugriffsrechte, Aktualisierung, Quellenanzeige und saubere Grenzen zwischen Teams.
Das ist wichtig. Aber es löst nur die Frage: Wo steht etwas?
Viele Unternehmen verwechseln das mit Unternehmensgedächtnis. Das ist zu bequem.
Retrieval kann sagen: Hier ist das Dokument, das wahrscheinlich passt. Es versteht aber nicht automatisch, welche Klausel in welchem Vertragsteil welche Wirkung hat. Es weiß nicht zwingend, ob eine alte Ausnahme noch gilt. Es kann nicht allein erklären, warum zwei Dokumente widersprechen oder welche Regel im Konflikt Vorrang hat.
Retrieval ist ein Bibliothekar. Kein Betriebsarchitekt.
2. Dokumente verstehen: Struktur und Bedeutung
Die zweite Schicht ist schwieriger.
Viele Unternehmensdokumente sind nicht einfach Text. Sie haben Struktur: Abschnitte, Anhänge, Klauseln, Versionen, Tabellen, Gültigkeiten, Verantwortlichkeiten, Ausnahmen, Querverweise.
Ein Vertrag ist nicht nur ein langer Text. Eine Policy ist nicht nur eine PDF. Ein technisches Handbuch ist nicht nur ein Suchtreffer. Ein Pitchdeck ist nicht nur Folieninhalt. Die Bedeutung liegt oft in der Struktur.
Dafür braucht man andere Architektur als für reines Retrieval. Man braucht Parsing, Segmentierung, Dokumentmodelle, Versionierung, Validierung und manchmal domänenspezifische Extraktion. Sonst findet der Agent zwar das richtige Dokument, versteht aber die falsche Ebene.
Das ist der Unterschied zwischen „such mir die Policy“ und „sag mir, welche Ausnahme in diesem Fall wirklich gilt“.
Wer nur Retrieval baut, bekommt schnelle Fundstellen. Aber nicht automatisch belastbares Dokumentverständnis.
Für reines Retrieval müssen Dokumente in "chunks" zerlegt und beispielsweise in mathematisch vergleichbare Vektoren übersetzt werden. Für semantische Struktur darf ein Dokument eben gerade nicht zerlegt werden. Um hier ein Beispiel für den Unterschied in der Architektur zu zeigen.
3. Tabellen und Beziehungen: das operative Netz
Die dritte Schicht sitzt in Tabellen, Datenbanken und Beziehungen.
Kunden, Produkte, Verträge, Tickets, Fälle, Kampagnen, Maschinen, Ersatzteile, Lieferanten, Accounts, Berechtigungen. Unternehmensrealität ist nicht nur dokumentiert. Sie ist relational.
Ein Agent, der Arbeit wirklich unterstützen soll, muss nicht nur wissen, dass es einen Vertrag gibt. Er muss wissen, welcher Kunde, welches Produkt, welcher Fall, welche Region, welcher Risikostatus und welche Freigabe damit zusammenhängen.
Das ist nicht dasselbe wie Dokumenten-RAG.
Hier geht es um Datenmodelle, Entity Resolution, Knowledge Graphs, Datenqualität, Berechtigungen und saubere Semantik. Wenn zwei Systeme denselben Kunden unterschiedlich schreiben, ist das kein Prompt-Problem. Wenn ein Agent Beziehungen falsch zieht, entsteht nicht nur schlechter Text. Es entstehen falsche Entscheidungen.
Viele Unternehmensagenten werden genau hier landen, weil die eigentliche Arbeit nicht im Schreiben von Antworten liegt. Sie liegt im Verbinden von Fällen, Daten, Dokumenten und Entscheidungen.
4. Arbeitsverläufe: Entscheidungen, Ausnahmen, Routinen
Die vierte Schicht ist die gefährlichste.
Sie entsteht nicht in Dokumenten und nicht in Tabellen, sondern in wiederholter Arbeit.
Welche Antwort akzeptiert ein Team? Welche Ausnahme wird immer eskaliert? Welche Formulierung streicht Legal jedes Mal? Welche Quelle vertraut der Fachbereich wirklich? Welche Kundengruppe bekommt Sonderbehandlung? Welche Senior-Person gibt informell grünes Licht, obwohl sie im Prozess nicht auftaucht?
Das ist gelebte Betriebsintelligenz.
Agenten können diese Schicht erstmals systematisch sammeln: über Prompts, Feedback, Session Transcripts, Tool Calls, Korrekturen, Evals, Freigaben und Memory Stores. Genau dort wird es strategisch.
Denn diese Schicht ist wertvoll. Und schlecht portabel.
Wenn sie beim Anbieter liegt, liegt dort nicht nur Kontext. Dort liegt ein Teil der Art, wie das Unternehmen arbeitet.
Der Anbieterwechsel wird zur Rekonstruktion
Genau hier wird der Vergleich mit einer Migration weg von SAP vielleicht treffend, vielleicht etwas bös.
Ganz ehrlich: Eine SAP-Migration ist furchtbar, aber sie hat eine erkennbare Aufgabe: Daten, Prozesse, Schnittstellen und Berechtigungen müssen in eine neue Landschaft übertragen werden. Man kann das Projekt falsch planen. Man kann es unterschätzen. Man kann sich daran ruinieren. Kommt alles vor. Die Wahrscheinlichkeit ist deutlich größer null, dass eine SAP-Migration eher ein Karriere-Killer als ein Karriere-Boost ist.
Aber immerhin weiß man ungefähr, was migriert werden muss. Was einen erwartet.
Bei agentischem Memory ist das schwieriger. Der Verlust liegt nicht nur in Dateien oder Datenbanken, sondern in Verdichtungen.
Ein Agent hat über Monate (vielleicht Jahre) gelernt, welche Quelle in welchem Kontext zählt. Welche Ausnahme kein Sonderfall mehr ist. Welche Freigabe in der Praxis wirklich gebraucht wird. Welche Formulierungen bei welchem Kunden nicht funktionieren. Welche Hinweise Senior-Leute geben, wenn ein Output fast richtig, aber eben nicht gut genug ist.
Beim Anbieterwechsel bekommt man vielleicht Rohmaterial heraus: Logs, Transcripts, Embeddings, exportierte Memories, Prompts, Konfigurationsdateien, vielleicht sogar Evals. Und nichts davon ist aktuell gesichert. Kaum ein Anbieter spricht darüber, wie man "wieder weggehen kann".
Außerdem, selbst wenn, ist Rohmaterial nicht dasselbe wie Arbeitsfähigkeit.
Ein Export kann technisch vollständig und operativ trotzdem halb wertlos sein. Weil die Semantik fehlt. Weil Feedback nicht sauber typisiert ist. Weil ein Memory-Eintrag ohne Kontext nicht mehr verständlich ist. Weil Evals an einen bestimmten Harness gebunden sind. Weil Toolaufrufe ohne Zielsystem keine Bedeutung mehr haben. Weil niemand dokumentiert hat, welche gelernte Routine kritisch war und welche nur Komfort.
Das ist der Unterschied zwischen Migration und Rekonstruktion.
Migration heißt: Wir übertragen ein bekanntes System.
Rekonstruktion heißt: Wir versuchen herauszufinden, was das System über uns gelernt hatte.
Genau deshalb ist diese Debatte praktischer, als sie zuerst klingt. Nicht weil jeder Anbieter böse ist. Sondern weil erfolgreiche Agenten zwangsläufig nah an wiederholter Arbeit sitzen. Je nützlicher sie werden, desto mehr Betriebserfahrung sammelt sich in ihnen.
Die nächste Frage ist nicht Anbieter. Sie ist Architektur
Hier liegt der zentrale Fehler in vielen AI-Programmen.
Sie reden über „den Agenten“, als gäbe es eine Architektur, die alles kann.
Gibt es nicht.
Ein Suchindex löst kein Dokumentverständnis. Ein Dokumentparser löst keine relationalen Datenprobleme. Ein Knowledge Graph löst keine informellen Freigaberoutinen. Ein Chat-Memory löst keine Auditierbarkeit. Ein Eval-Harness löst keine Datenqualität. Und ein multimodales Modell beantwortet nicht die Frage, wem seine Interpretationen später gehören.
Das ist keine akademische Unterscheidung. Das ist der Unterschied zwischen einem brauchbaren Piloten und einer teuren Abhängigkeit.
Die erste Frage vor jedem Agenten-Job lautet deshalb:
Welche Art von Gedächtnis braucht dieser Workflow wirklich?
Ein Policy-Assistent braucht vor allem Dokumentstruktur. Ein Schadenprozess braucht Beziehungen zwischen Vertrag, Schadenfall, Ausnahme und Entscheidung. Marketing und Beratung brauchen Briefinglogik, Freigaben, Markenmuster und gelernte Kundenpräferenzen. Technischer Service braucht Handbücher, Ersatzteile, Maschinenhistorie und Fehlerbilder.
Wer das nicht trennt, kauft am Ende eine schöne Demo. Und wundert sich später, warum sie im Betrieb nicht trägt.
Der Markt löst Schichten, nicht das Ganze
Das ist der unbequeme Teil.
Kein Anbieter hat dieses Problem bisher vollständig gelöst.
Microsoft, Google, Glean, Salesforce, ServiceNow, Atlassian, SAP, Workday und Notion sitzen nah an bestehenden Arbeitsoberflächen und Systemen der Wahrheit. Das ist stark, weil dort echte Arbeit passiert. Es ist aber auch riskant, weil genau dort Kontext, Gewohnheit und Default-Sog entstehen.
Andere Anbieter lösen kontrollierbarere Bausteine: deepset, Elastic, Weaviate, Qdrant, Neo4j, Graphwise, Langfuse, Braintrust oder Arize Phoenix. Sie geben mehr Kontrolle über Retrieval, Graphen, Evals oder Traces. Dafür verlangen sie mehr Architektur- und Betriebskompetenz.
Dann gibt es die neue Memory-Schicht: Zep, Mem0, Letta, Anthropic Managed Agents und ähnliche Ansätze. Dort wird sichtbar, wohin die Reise geht: persistente Agenten, Graph-Memory, Traces, Evals, Memory-Reorganisation. Spannend. Aber für deutsche und europäische Unternehmen noch nicht automatisch beschaffungsreif.
Die Marktkarte zeigt deshalb keinen Gewinner.
Sie zeigt Schichten.
Und genau das ist der Punkt: Ein Anbieter kann in einer Schicht stark sein und in einer anderen schwach. Ein gutes Modell macht noch kein gutes Unternehmensgedächtnis. Eine gute Admin-Konsole macht noch keine Exit-Architektur. Ein überzeugendes Demo-Memory sagt noch nichts darüber, ob Evals, Traces und Arbeitsroutinen in zwei Jahren verständlich, löschbar und portabel sind.
Für Einkauf und Management ist das unbequem. Die alte SaaS-Frage war einfacher: Serverstandort, AVV, Rollenmodell, Exportfunktion, Preis.
Alles weiterhin wichtig.
Aber nicht mehr ausreichend.
Die neue Frage lautet:
Welche Teile unserer Arbeit lernt dieses System, in welcher Form, mit welchem Besitzer und mit welcher Wechselmöglichkeit?
Wenn ein Anbieter darauf keine präzise Antwort hat, ist das kein Detail für später. Es ist der Kern der Entscheidung.
Nicht alles selbst bauen. Aber wissen, was man besitzt.
Das heißt nicht, dass Unternehmen jetzt alles selbst bauen müssen.
Das wäre die nächste schlechte Idee. Kaum ein Mittelständler sollte plötzlich eigene Memory-Infrastruktur, eigene Evals, eigene Graphen und eigene Agent-Runtimes betreiben. Auch viele Konzernteams sollten das nicht ohne Not tun.
Aber Unternehmen müssen wissen, welche Schichten sie einkaufen und welche sie besitzen wollen.
Betrieb kann ausgelagert werden. Verantwortung nicht.
Komfort kann beim Anbieter liegen. Kritisches Unternehmensgedächtnis braucht mindestens Spiegelung, Export, Audit und klare Besitzregeln.
Sonst merkt man erst beim Wechsel, dass man nicht nur ein Tool genutzt hat. Man hat einem Tool beigebracht, wie die eigene Organisation funktioniert.
Früher ging es darum, wer das beste Modell hat. Dann darum, wer die besten Tools anschließt. Als Nächstes geht es darum, wer das Gedächtnis hält.
Memory wird zur strategischen Schicht.
Nicht weil Memory hübsch personalisiert. Sondern weil dort Kontext, Routine, Bewertung und Exit-Kosten zusammenlaufen.
In Deutschland wird das schnell konkret
Für deutsche und europäische Unternehmen ist das keine reine Plattformfrage.
Sobald Agenten Arbeitsroutinen speichern, entstehen Datenschutz-, Mitbestimmungs-, Audit- und Governance-Fragen.
Datenschutz fragt, welche personenbezogenen Daten in Memory, Logs, Feedback und Agententraces landen. Art. 35 DSGVO macht Datenschutz-Folgenabschätzungen dort relevant, wo neue Technologien voraussichtlich hohe Risiken für Rechte und Freiheiten erzeugen. Art. 22 DSGVO ist enger und gilt nicht für jeden Agenten. Aber sobald automatisierte Entscheidungen rechtliche oder ähnlich erhebliche Wirkung entfalten, wird die Linie hart.
Mitbestimmung fragt, ob Arbeitsverhalten sichtbar, bewertbar oder steuerbar wird. § 87 Abs. 1 Nr. 6 BetrVG ist dafür der nüchterne deutsche Anker: Der Betriebsrat hat mitzubestimmen bei technischen Einrichtungen, die dazu bestimmt sind, Verhalten oder Leistung von Arbeitnehmern zu überwachen.
Ein Agentensystem mit Logs, Memory, Produktivitätsmetriken und individuellen Feedbackspuren kann sehr schnell in diese Zone geraten.
Der AI Act legt eine weitere Schicht darüber. Art. 4 verlangt AI Literacy bei Anbietern und Betreibern. Art. 14 beschreibt Human Oversight für Hochrisikosysteme. Art. 26 formuliert Pflichten für Deployer von Hochrisikosystemen. Nicht jeder Unternehmensagent ist automatisch Hochrisiko. Aber die Richtung ist klar: Wer AI produktiv einsetzt, muss Menschen, Aufsicht und Nutzungskontext ernst nehmen.
Das ist kein Grund, nichts zu tun.
Es ist ein Grund, die Architektur nicht dem bequemsten Anbieter-Default zu überlassen.
Was vor dem nächsten Pilot geklärt sein muss
Die falsche Frage lautet:
Welcher Anbieter hat das beste Agent-Memory?
Die bessere Frage lautet:
Welche Art von Gedächtnis darf bei uns überhaupt wo liegen?
Vor dem nächsten Agenten-Pilot sollten vier Dinge geklärt sein.
1. Workflow klassifizieren
Geht es vorrangig um Retrieval, Dokumentverständnis, relationale Daten, Arbeitsverläufe, multimodale Wahrnehmung oder Orchestration?
2. Ownership festlegen
Welche Teile dieses Gedächtnisses müssen der Organisation gehören, unabhängig vom Modell- oder Toolanbieter?
3. Exit simulieren
Was wäre nach zwölf Monaten Anbieterwechsel wirklich verloren: Dateien, Prompts, Evals, Feedback, Traces, Arbeitsroutinen, Beziehungen oder Kundenpräferenzen?
4. Governance vor den Pilot ziehen
Welche Daten, Logs, Feedbackspuren und Bewertungsmuster berühren Datenschutz, Betriebsrat, Audit oder Compliance?
Das ist weniger bequem als „wir testen mal einen Agenten“.
Aber genau dort entsteht Lock-in: nicht beim Vertragsschluss, sondern wenn ein erfolgreicher Pilot zur Gewohnheit wird.
Zwei Werkzeuge für die nächste Entscheidung
Damit diese Fragen nicht abstrakt bleiben, habe ich zwei Anschlussstücke vorbereitet.
Die Werkbank zur Agentic-Memory-Architektur hilft dabei, einen konkreten Workflow zu zerlegen: Welche Gedächtnisschichten braucht er, welche Risiken entstehen, was muss exportierbar bleiben?
Der Agentic Memory Vendor Radar für DE/EU ordnet Anbieter und Bausteine entlang dieser Schichten ein. Nicht als Bestenliste. Sondern als Marktkarte: Wer sitzt nah an der Arbeitsoberfläche? Wer bietet kontrollierbare Infrastruktur? Wo entstehen Traces, Graphen, Evals oder Memory Stores? Und welche DE/EU-Fragen müssen vor einem Pilot auf den Tisch?
Wer nur wissen will, „welcher Anbieter gut ist“, wird dort nicht glücklich.
Wer wissen will, welche Abhängigkeit er sich gerade baut, schon eher.
Der eigentliche Test
Die nächste Anbieterentscheidung sollte nicht nur durch IT, Legal und Procurement laufen. Sie braucht eine Memory-Architekturfrage.
Sie lautet:
Wenn wir diesen Anbieter in zwei Jahren wechseln müssten, was könnten wir exportieren, und was müssten wir organisatorisch neu lernen?
Wenn die Antwort nur Dateien, Nutzerkonten und Vertragsklauseln nennt, ist sie unvollständig.
Denn der härteste Lock-in entsteht nicht dort, wo Daten gespeichert werden. Er entsteht dort, wo ein System gelernt hat, wie Arbeit in einer Organisation wirklich läuft.
Der alte Lock-in saß in Systemen, die man wenigstens kartieren konnte.
Der neue sitzt im Unternehmensgedächtnis.
Praktischer Test zum Essay
Drei Vorlagen für ein Gespräch mit einer KI: Ziel klären, Widersprüche prüfen, Delegierbarkeit testen. Du bekommst keine fertige Strategie und keine Tool-Empfehlung.
Vorlagen öffnenTiefer einsteigen
Drei Anschlussstücke, wenn du den Gedanken vertiefen willst.
Der neue Lock-in sitzt im Gedächtnis
APIs lassen sich wechseln. Gewohnheiten, Freigaben und gelernter Kontext viel schwerer. Warum der nächste große AI-Lock-in tiefer sitzen könnte als …
Warum AI-Tools scheitern – und wo der Hebel liegt
Der Engpass ist nicht die Software. Es ist das Wissen, das nur in Köpfen existiert. Warum institutioneller Kontext der eigentliche Hebel ist – und …
Das falsche Black-Box-Problem
Nicht das Modell ist oft das größte Rätsel, sondern das Unternehmen selbst: Regeln fehlen, Wissen steckt in Köpfen, Entscheidungen werden offiziell …