Artifact Production Just Got Cheap
What remains when code costs nothing
Practical test for this essay
Three templates for a conversation with an AI: clarify the goal, check contradictions, test whether the work can be delegated. You do not get a finished strategy or a tool recommendation.
Open the templatesA Goldman Sachs analyst needs a day for an operating model. A guy with Claude needs thirty minutes. Inference costs have dropped by a factor of 50 in three years, and with that, every knowledge work artifact becomes a commodity: slides, analyses, code, reports. The consulting pyramid is breaking because its base is being automated. In most strategy meetings, the question still isn't being asked: If the artifact costs nothing, what are we actually selling?
Stay up to date
Get notified when I publish something new, and unsubscribe at any time.
Last week, someone built a complete operating model in ten minutes. Revenue projections, cost structure, unit economics, scenario analysis. Everything linked, everything clean. Then he told Claude in PowerPoint: Build me the board deck. Five slides, executive summary, financials, key metrics, risks, asks. Twenty minutes later, he had a presentation that looked like his team had spent two days on it. Charts referencing the live data in Excel. Formatted in his company's colors and fonts.
A Goldman Sachs analyst looked at the model and said: solid. The kind of output that would have taken him a full day.
Thirty minutes. From an empty spreadsheet to a board-ready presentation.
(Nate B. Jones described this in detail in his newsletter "I built in 10 minutes what takes a Goldman analyst a day" -- including the prompts he used. Worth reading.)
This isn't a demo. This is a product that exists today, for twenty dollars a month. And it gets better every quarter, automatically, overnight, without anyone installing an update.
Not an Anthropic ad -- the tool will probably have a different name next year. But the question remains: What happens to us when the cost of producing knowledge work artifacts drops to near zero?
I work in the agency industry. Every day I see how organizations react to this shift -- or don't. Platforms that cost hundreds of millions and promise content at scale. Teams that suddenly produce in ten minutes what took them three days last week. And a question that still isn't being asked in most strategy meetings: If the artifact costs nothing -- what are we actually selling?
Artifacts Are Becoming Commodities
Let's start with the numbers.
Inference costs for large language models are dropping fast. Epoch AI measured: the price decline ranges from a factor of 9 to a factor of 900 per year, depending on performance level. The median is a factor of 50. Andreessen Horowitz calls the trend "LLMflation" and puts it at a factor of 10 per year -- faster than the price drop in processors during the PC revolution, faster than bandwidth during the dotcom boom.
Specifically: GPT-4-equivalent performance costs $0.40 per million tokens today. At the end of 2022, it was $20. A factor of 50 in three years.
Tokens cost electricity. The foundation models are in a price war. DeepSeek disrupted the market with 90 percent lower prices. OpenAI responded with 80 percent price cuts. The direction is clear, and it's accelerating.
What does this mean in practice? Code, analyses, presentations, dashboards, reports -- everything that can be called "output" is becoming cheap. Not free. But marginal costs are falling so fast that the difference to zero becomes irrelevant for most business models.
(Yes, there are counterarguments. More on that in the honesty test below.)
This is the desktop publishing moment of knowledge work. In the 90s, desktop publishing suddenly allowed everyone to lay out brochures. It didn't make graphic designers obsolete. But it fundamentally shifted the value -- away from the ability to produce a layout, toward the ability to recognize a good layout and commission one.
We're at exactly that point, except this time it's not about layouts -- it's about all of knowledge work. Operating models. Board decks. Competitive analyses. Due diligence packs. Pitch decks. Quarterly reports. Every single artifact that used to require hours or days of human labor can now be produced in minutes. Not in poor quality. In a quality that a Goldman analyst calls "solid."
This doesn't change one profession. It changes the foundation on which companies create value.
The Pyramid Is Breaking
If you want to understand what this means concretely, just look at the consulting industry.
McKinsey, BCG, and Bain have frozen starting salaries for the third consecutive time. PwC cut graduate hiring in 2025. Two senior executives at Big Four firms estimate that graduate hiring at the largest British consulting firms will drop by half in the coming year. The Harvard Business Review describes the shift from the classic pyramid model to the "obelisk" -- fewer layers, smaller teams, AI taking over the work that junior consultants used to do.
The pyramid model of the big consulting firms is based on simple economics: research, analysis, and deck building are expensive because they cost labor time. Many junior consultants at the base of the pyramid produce artifacts that a few partners at the top package into judgment and sell to clients. Revenue equals time times expertise.
AI compresses the time component. An analyst slot can be replaced by a model that never sleeps and doesn't bill overtime. The pyramid becomes more profitable -- for the firms. Because here's the uncomfortable truth: Day rates haven't fallen. Project fees look suspiciously familiar. AI has lowered delivery costs, but the benefits remain trapped in the firms' P&Ls. For now.
Namaan Mian, COO of Management Consulted, puts it this way: the ability to extract more value from fewer junior employees puts downward pressure on compensation. In professional services and tech, AI-driven disruption is more real than in other economic sectors.
What's already happening: new, AI-native boutique consultancies are emerging, founded by former Big Four partners. Mark Bunker, former Deloitte Senior Partner and now Managing Partner at Queen's Tower Advisory, says: the base of the pyramid will shrink, but the need for experienced judgment at the top will become more critical. Antonio Alvarez of Alvarez & Marsal describes the "box model" -- a structure where senior and junior staff are numerically closer than in the classic pyramid.
The question isn't whether the pricing pressure reaches the clients. The question is when. And when it does, it's not just a business model that breaks -- it's a paradigm. Because the consulting pyramid is just the most visible example. The same pattern applies to agencies, to internal analytics teams, to any organization whose value creation is based on producing knowledge work artifacts.
In Germany, there's an additional factor that doesn't appear in the US analyses: works councils. When the pyramid breaks, that's a co-determination process. It slows the transformation down. But it also forces companies to think the shift through rather than just letting it happen. If you have to explain to a works council why twenty analyst positions are being eliminated and five spec positions are being created, you've documented your decision architecture. That's not a disadvantage. That's a byproduct most US firms never get forced into.
When the artifact becomes cheap, value has to live somewhere else.
The question is: Where?
McKinsey's State of AI 2025 study found that the organizations with the best AI results aren't the ones with the most tools. They're the ones that fundamentally redesigned their workflows, using AI as a catalyst for fundamental change rather than an accelerator for existing processes. High performers invest more than 20 percent of their digital budget in AI technologies and are three times more likely to rethink individual workflows from scratch.
This confirms my observation: the advantage doesn't lie in the speed of artifact production. It lies in what artifact production doesn't automate -- and never will.
Three Things AI Doesn't Make Cheaper
The big service organizations are investing in execution. Platforms that scale artifact production. The question nobody's asking: Who's investing in what remains valuable?
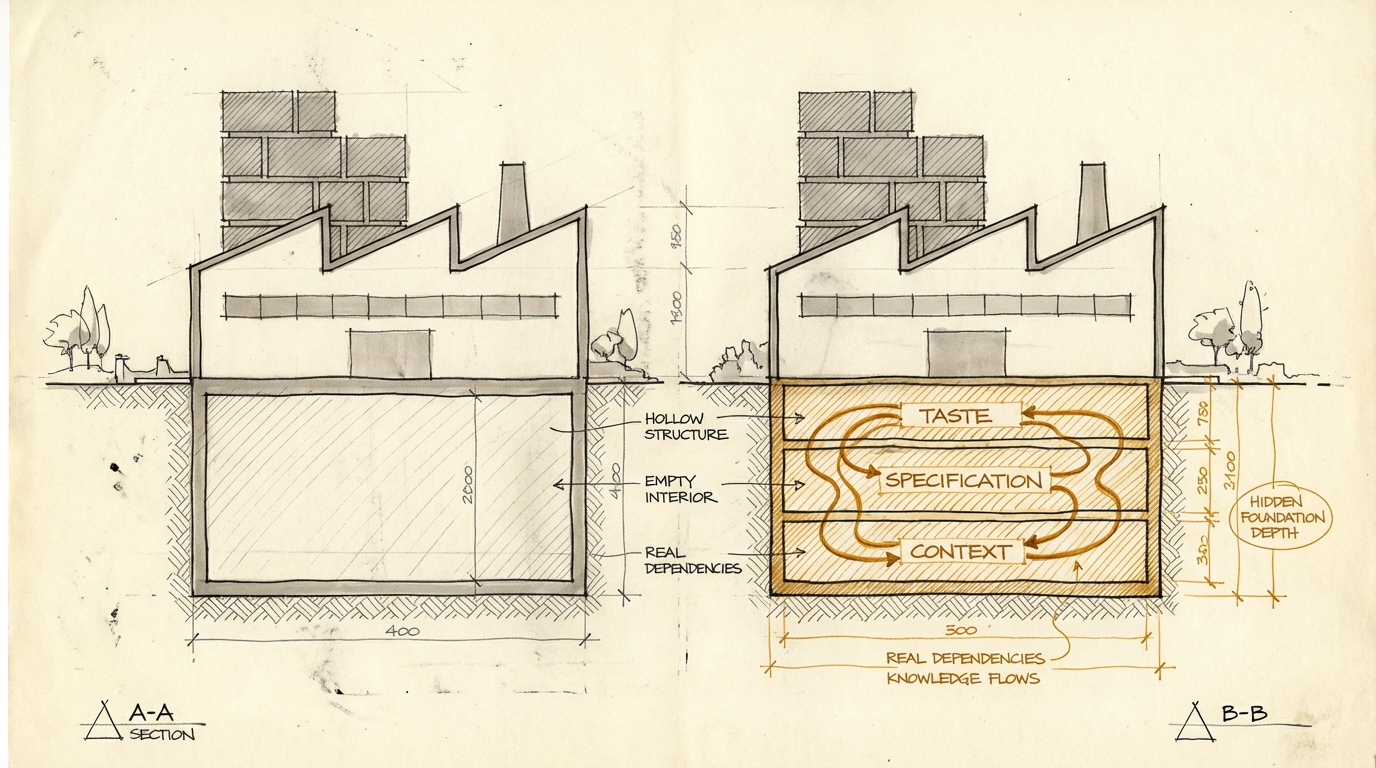
1. Taste -- who decides what's good?
I don't mean taste in the aesthetic sense. I mean judgment. The ability to select the right thing from the space of possibilities.
When Claude builds five technically correct board presentations -- who decides which one tells the right story? When an operating model shows three scenarios -- who knows which one the board needs to see? When an analysis delivers twenty data points -- who recognizes which three drive the decision?
That's taste. It's the ability to ask the right question before the model starts running. It's knowing what framing a problem needs. It's the experience to recognize that a technically correct analysis is answering the wrong question.
And here's the paradox: The cheaper artifacts become, the more important taste gets. Because the volume of possible output grows exponentially, while the ability to distinguish signal from noise stays constant. Taste is the only filter. And it doesn't scale.
A Stanford study, published in the Harvard Business Review, measured what happens when it's missing: 40 percent of 1,150 full-time employees had already received AI-generated "workslop" from colleagues. Technically competent, substantively empty. The estimated productivity cost: $186 per employee per month in wasted time spent processing professional-looking output that says nothing.
The board deck Claude builds in thirty minutes looks identical. Whether someone spent an hour thinking about the strategy -- or typed "make me a board deck about our Q1 results" and went to get coffee. The format is clean. The charts are right. The layout is professional. The difference between the two outputs -- between insight and slop -- is invisible to the tool. It's only visible to the human who decides.
The human who says: "Stop. Wrong comparison group. Again, but with these three competitors." That's taste. Models recognize patterns and reproduce them -- but they don't know which patterns are relevant in this context.
Steve Yegge recently introduced a framework he calls "Software Survival 3.0." His argument: when compute resources are limited, software that saves cognition survives. What would be absurdly expensive to synthesize from scratch stays. What's easily replicable gets replicated and becomes worthless.
He formalizes this as the Survival Ratio: the cognitive benefit of a tool divided by the cognitive cost of knowing and using it. Tools with a ratio above 1 survive. Tools below get bypassed.
Applied to companies: taste is judgment that grew over years. It would be absurdly expensive to rebuild from scratch. It emerges from thousands of decisions, from the accumulated knowledge of what works in a specific market, for a specific audience, in a specific context. No model can replicate that, because it never had the context. It can produce artifacts. It can't know whether they're the right artifacts.
The consequence is uncomfortable: in teams that were previously defined by execution -- who builds the best model, who makes the cleanest slides -- value shifts entirely. Execution gets delegated. What remains is the ability to make the right decision before execution. And to critically evaluate the output after execution. The middle third -- the actual production -- becomes the smallest part of the value contribution.
But taste isn't a moat you can rest behind. It's a lead that decays if you don't maintain it. (How fast it decays and why -- more on that in the honesty test below.)
2. Brand as Lived Differentiation
When everyone can produce the same artifacts -- the same slides, the same analyses, the same dashboards -- what distinguishes your company from the competition?
The answer isn't the logo. It's the experience.
Brand is how the interaction with your company feels. The consistency. The tonality. The way information is structured. The moment a customer notices: this is different from the others. Not better formatted. Differently thought through.
You can already see this. Take two agencies using the same AI tool to develop a campaign strategy. Both produce a strategy deck with audience analysis, competitive landscape, channel recommendation. The artifacts look similar -- because the tool produces similar artifacts. What differentiates the clients isn't the deck. It's the perspective embedded in the deck.
It's the point where an agency says: "We recommend channel X because we know from experience that your audience reacts differently there than the market average." That's brand in the sense of: a recognizable, experience-based stance that can't be copied because it emerges from accumulated context.
When AI allows every company to produce professional artifacts, professionalism becomes the baseline. It's no longer a differentiator. What differentiates is what sits above professionalism: the specific perspective, the specific way of framing problems, the specific stance a company takes.
This isn't an aesthetic argument. It's an economic one. Brand is based on accumulated trust and recognition. Neither can be built overnight and neither can be copied. When artifacts become cheap, it's one of the few differentiation levers that remains.
And brand now has to become more explicit. When a consultant used to spend two days on a deck, brand flowed in implicitly -- through the person, the way they think, the way they present. When a model now builds the deck, brand has to be passed along as a constraint. Design systems, tonality guidelines, UX principles -- everything that used to be implicit knowledge has to become machine-consumable. If you don't have that, you get generic artifacts in your company colors. That's not brand. That's a template.
3. The Data Model as Competitive Advantage
Every company has data. Customer data, product data, market data, transaction data. Most companies know this. Many talk about data being "the new oil." Few have made something useful out of it.
The numbers are sobering. Only 6 percent of companies consider their data infrastructure AI-ready. 71 percent of AI teams spend over a quarter of their time on "data plumbing" -- trying to wrangle chaotic, heterogeneous, poorly documented data into a form a model can work with. 53 percent of companies struggling with AI implementation fail because of immature data systems.
But the data itself isn't the value. The value is the data model. Meaning: how has a company understood its domain and translated it into structures?
Why now? Because it's becoming clear that code itself is turning into a fleeting intermediate result -- a temporary cache that can be regenerated from a specification at any time. When code becomes interchangeable, the data model is the only software artifact with lasting value. Not the code that operates on it. Not the interface that displays it. The model of reality that the company wants to represent.
A data model is domain knowledge translated into structure. It's the taxonomies, the relations, the schemas that map how a company thinks about its customers, its products, its market. It's the answer to the question: What are the entities in our business, and how are they connected?
Sounds abstract. It isn't.
Take two companies in the same industry. Company A has its customer data in a clean schema: customer types, segments, lifecycle stages, product affinities, interaction history -- all in a consistent structure with clear definitions and relations. Company B has the same data, but spread across seven systems, with inconsistent labels, no documented relations, duplicates, and gaps.
Now both add an AI layer. Company A gives the model a schema that can be understood in 500 tokens. The model can immediately run meaningful analyses, spot patterns, generate recommendations. Company B has to first explain to the model where the data lives, what the fields mean, why "customer type" means something different in system 3 than in system 5. That costs thousands of tokens, produces more errors, and delivers worse results.
This isn't a technical detail. It's an economic difference. Every token spent on context explanation is a token not used for analysis. Token efficiency is the new metric for data model quality. And token efficiency translates directly into lower costs and better outputs.
Steve Yegge calls the principle "Substrate Efficiency": some computations are absurdly expensive via LLM inference, even though they'd be trivial with classical software.
The same principle applies to enterprise data. The smartest approach isn't to push everything through an LLM -- but to build an architecture that computes what's computable and only uses the model where interpretation, synthesis, or judgment is actually needed.
This is an architecture decision with strategic consequences: it determines how expensive and how good AI applications work. Those with a token-efficient data model pay less per query, get better results, and can economically run more use cases than the competitor with data chaos.
Databricks and the MIT Technology Review confirm this: competitive differentiation increasingly comes from the data and governance layers underneath the AI, not from the model itself. The organizations making real progress invest in semantic context and an architecture that allows models to operate on trustworthy data.
3M provides a concrete example: their data and AI teams focus on building deeper metadata and business context before scaling agentic capabilities. By strengthening the semantic layer behind their data, they ensure that every model and every agent has the clarity to make reliable decisions. Context isn't a technical detail for them -- it determines the quality of every analysis.
The analogy: The LLM is the engine. The data model is the road. A Formula 1 engine on a dirt road is slow and expensive. The same engine on a highway is fast and efficient. Companies are currently investing billions in better engines. Almost nobody is investing in the road.
Building a good data model isn't a question of technology. It's a question of domain knowledge. It requires someone who understands how the business works and translates that understanding into structures.
No AI can do this for a company -- it doesn't know the business from the inside. It knows patterns from training, but not the reason why a specific customer segment works differently in this market than in that one. That knowledge lives in the heads of employees. Translating it into a machine-consumable schema is one of the most valuable investments a company can make right now.
The German Mittelstand in particular has an advantage here that it often doesn't see. A machine builder in Swabia who has been making specialty gears for thirty years has domain knowledge in the heads of its engineers that no foundation model can replicate. The question is whether the company translates that knowledge into a machine-readable schema -- or whether it gets lost with the next wave of retirements.
Where I Could Be Wrong
Three counterarguments with substance.
First: Reasoning models are driving costs up, not down. New models "think" internally before they answer. More tokens per task, higher costs per task. That's true in isolation. But the quality of results improves with every model upgrade: fewer retries, fewer corrections, less human rework. The net effect on total costs per usable result is falling. The question is how fast. And whether model providers pass the efficiency gains on to customers or pocket them as margin. That's open.
Second: Taste decays faster than you'd think. The AI baseline rises with every model upgrade. What requires human judgment today might be handled better by a model in a year. The lead that taste provides is real, but its half-life is unclear. In a tech startup: maybe months. In German industry with its regulatory peculiarities: probably years. Anyone who relies on taste as a permanent moat without actively sharpening it will be caught off guard. Taste remains valuable. But only as a practice, not as an entitlement.
Third: The timing. I'm arguing as if the shift is here. For some industries, that's true. For others, it's still two or three years away. The consulting pyramid isn't breaking tomorrow -- it's eroding. The question of whether to invest now or wait is legitimate. My argument: investing in taste, brand, and data model has value even without AI. You're not building AI-specific assets, you're building better decision architectures. That pays off either way.
And still: The direction of costs is unambiguous. A factor of 50 in three years leaves no room for interpretation. Even if the timing varies by a year or two: anyone who waits until artifact production actually costs zero has missed the investment window for what will matter then.
What Companies Should Do Now
Enough diagnosis. Here's what follows. Not as a five-year roadmap, but as questions every company should ask that wants to stay relevant when artifacts become cheap.
Taste Is a Leadership Job
Taste can't be delegated. It can't be handed to the IT department, not to an "AI Center of Excellence," not to a service provider. Taste is what leadership exemplifies. Or doesn't.
PwC measured this: bottom-up crowdsourcing of AI initiatives produces impressive adoption numbers. It rarely produces useful results.
Three consequences.
Leadership must set the quality standard. If the C-suite rubber-stamps every AI output because it "looks professional," the organization doesn't have an AI problem. It has a leadership problem.
The most valuable decision in a world of cheap artifacts is "we're not doing that." Killing professional-looking output because it answers the wrong question -- that has to come from leadership. As a cultural norm, not a control mechanism.
Transformation needs more than tools. "Just go for it" isn't enough. Teams need time, space, and guidance to learn when AI output is good enough and when it isn't. When a model delivers the right analysis and when it gives a technically correct answer to the wrong question.
This is change management, not an IT rollout. It requires leaders who work with the tools themselves, who know the difference between insight and slop from their own experience -- and who are willing to model that behavior.
Enablement, not control. It's not about regulating AI use. It's about creating a culture where judgment is rewarded -- not output volume.
This requires new metrics. Not "how many analyses did the team produce?" but "what decisions did the team enable?" Not "how fast was the output?" but "did the output answer the right question?"
Those who can define "fewer, but more correct" as a success metric have a cultural advantage that's worth at least as much as any technology investment.
Develop framing as a core competency. The most important skill when artifacts become cheap isn't production. It's framing. What question are we asking? What problem are we solving? For whom? With what goal?
This can be trained. It can be anchored as a practice in meetings, in briefings, in project setups. But only if leadership treats it as what it is: the most valuable competency in the company.
Practically, this means: every briefing starts with the question, not the tool. Not "let's have Claude build an analysis," but "what would we need to know to make this decision?" Only when the question is clear does production begin.
This sounds trivial. In practice, it's constantly skipped because the temptation to just start is strong -- the tool is right there, the output comes in minutes. But ten minutes of thinking about the right question saves hours of artifact production nobody needs.
And it also means: introduce kill meetings. Regular reviews where the question isn't "what did we produce?" but "what of that enabled a decision -- and what can we shut down?"
When production is cheap, the ability to not do things is more valuable than the ability to produce more. But this ability doesn't emerge on its own. It has to be culturally willed, modeled by leadership, and structurally enabled.
The Data Model Audit
Most companies don't know what state their data is in. Three questions that create clarity:
1. Can we describe our core entities in one sentence?
"Customers buy products in categories, each purchase has a channel and a timestamp." That's a data model. If the answer is instead "you'd have to look at that in detail," there are tables, but no model.
2. How long does a new analyst need to understand our data?
Three months? Then an LLM needs the same amount of context. Except it pays in tokens, not in months. And that gets expensive, with every single query.
3. How token-efficient is our schema?
Can an LLM understand our data structure in 500 tokens -- or does it need 50,000? A schema that can be explained in a few sentences produces better results at lower costs. This isn't a technical criterion. It's a strategic one.
The test: sit down with someone from your data team and try to explain your data model in five sentences. If you can, you have a model. If not -- then you have a problem that gets more expensive with every AI use case.
Not Everything Needs to Run Through an LLM
Anyone who accepts that inference costs electricity and electricity is finite arrives at a clear consequence: not everything should run through an LLM. The question is: What actually needs reasoning -- and what can be solved with classical software?
The principle: compute what's computable. Cache recurring queries. Make structured data accessible so the model can retrieve specifically rather than searching the entire context. And only use the LLM where interpretation, synthesis, or creative connection is actually needed.
The question for companies: What are the text searches of your business -- the routine tasks that run through a language model today even though classical software would solve them faster and cheaper? Yegge's Substrate Efficiency principle (see data model section) applies here as well: every token that doesn't have to flow through inference is saved cost.
This sounds like IT architecture. It is. But it's the kind of architecture decision that determines whether a company can run AI economically -- or discovers after the pilot that costs blow the budget.
Brand Must Become Machine-Readable
The implicit-to-explicit shift from the brand section has a practical consequence: if you want to pass brand along as a constraint, you need more than colors and fonts.
A concrete example: "The most important argument is always on slide 2, not slide 5." "Never more than three KPIs per slide." "Charts always have an action recommendation as subtitle, never just a description." These are rules that can be passed to a model. And they produce outputs that feel like the company -- not like a generic AI result in company colors.
The question isn't technical, it's intellectual: What makes our way of communicating specific? And can that be translated into rules a model can apply? If you don't do this work, you're leaving brand consistency to the default behavior of a foundation model that acts the same for all clients.
The Asymmetric Future
One final thought.
The tools get better every quarter. Automatically. Overnight. Without anyone doing anything. A new model is rolled out, and every installation in the world gets smarter overnight. The operating model that took ten minutes last week might take five next quarter. Quality will increase. Costs will decrease. That's one side.
Taste doesn't get better automatically. Brand doesn't build overnight. A data model doesn't emerge from a model upgrade. These three assets only get better when people work on them. Deliberately, over time, with judgment.
One scales on its own. The other doesn't. And that's exactly why it's valuable.
The platforms currently scaling artifact production aren't wrong. The efficiency gains are real. But they reach everyone. Every competitor has access to the same foundation models, the same inference costs, the same production speed. The platform isn't a competitive advantage. It's the new baseline.
The companies that instead -- or additionally -- invest in taste, brand, and their data model are building something that becomes more valuable with every model upgrade, not cheaper. Because the better the models get, the more artifacts more people can produce. And the more it matters who's asking the right questions, who has a recognizable perspective, and whose data is structured so that models can actually do something with it.
Those who invest in artifact production buy time. Those who invest in taste, brand, and data model build a position.
Artifact production just got cheap. The competition has just begun.
Sources and Further Reading
Primary References:
- Nate B. Jones: "I built in 10 minutes what takes a Goldman analyst a day + the 4 prompts to do it yourself" (February 2025) -- The operating model example and the analysis of Claude in Excel/PowerPoint
- Steve Yegge: "Software Survival 3.0" (January 2026) -- The Survival Ratio framework, Substrate Efficiency, and the cognition-saving thesis
Inference Costs and LLMflation:
- Epoch AI: "LLM inference prices have fallen rapidly but unequally across tasks" (March 2025) -- Price decline between a factor of 9 and 900 per year, median 50x -- epoch.ai
- Andreessen Horowitz: "Welcome to LLMflation" (November 2024) -- Factor 10 per year, faster than Moore's Law and Edholm's Law -- a16z.com
- Introl: "Inference Unit Economics: The True Cost Per Million Tokens" (February 2026) -- GPT-4 equivalent: $0.40/M tokens vs. $20 at end of 2022 -- introl.com
Consulting Industry:
- Slashdot / Financial Times: "Top Consultancies Freeze Starting Salaries as AI Threatens Pyramid Model" (December 2025) -- McKinsey, BCG, Bain freeze starting salaries for the third time; PwC cuts graduate hiring -- tech.slashdot.org
- Harvard Business Review: "AI Is Changing the Structure of Consulting Firms" (September 2025) -- From pyramid to obelisk model -- hbr.org
- ConsultingQuest: "How AI Is Changing Consulting Economics" (November 2025) -- Productivity Paradox: costs decrease, prices stay -- consultingquest.com
Data Infrastructure and AI Readiness:
- CData / BetaNews: "Just six percent of enterprises believe their data infrastructure is AI ready" (December 2025) -- 6% AI-ready, 71% data plumbing -- betanews.com
- Databricks / MIT Technology Review: "Infrastructure & Strategies Driving the Next Wave of Enterprise AI" (2025) -- Competitive differentiation from data and governance layers -- databricks.com
AI Strategy and Organizations:
- McKinsey: "The state of AI in 2025" (November 2025) -- High performers redesign workflows, invest >20% digital budget in AI -- mckinsey.com
- PwC: "2026 AI Business Predictions" (2025) -- Top-down programs vs. crowdsourcing; hourglass workforce model -- pwc.com
Workslop Study:
- Stanford / BetterUp, published in Harvard Business Review -- 40% have received AI-generated workslop; $186/month productivity cost per employee
Practical test for this essay
Three templates for a conversation with an AI: clarify the goal, check contradictions, test whether the work can be delegated. You do not get a finished strategy or a tool recommendation.
Open the templates