Artefaktproduktion just got cheap
Was bleibt, wenn Code nichts mehr kostet
Praktischer Test zum Essay
Drei Vorlagen für ein Gespräch mit einer KI: Ziel klären, Widersprüche prüfen, Delegierbarkeit testen. Du bekommst keine fertige Strategie und keine Tool-Empfehlung.
Vorlagen öffnenEin Goldman-Sachs-Analyst braucht einen Tag für ein Operating Model. Ein Typ mit Claude braucht dreißig Minuten. Die Inference-Kosten sind in drei Jahren um Faktor 50 gefallen, und damit wird jedes Wissensarbeit-Artefakt zur Commodity: Slides, Analysen, Code, Reports. Die Consulting-Pyramide bricht, weil ihre Basis automatisiert wird. In den meisten Strategiemeetings wird die Frage noch nicht gestellt: Wenn das Artefakt nichts mehr kostet, was verkauft man dann eigentlich?
Bleib auf dem Laufenden
Erhalte eine Nachricht, wenn ein neuer Essay erscheint. Jederzeit abbestellbar.
Letzte Woche hat jemand in zehn Minuten ein vollständiges Operating Model gebaut. Revenue-Projektionen, Kostenstruktur, Unit Economics, Szenarioanalyse. Alles verlinkt, alles sauber. Dann hat er Claude in PowerPoint gesagt: Bau mir das Board Deck dazu. Fünf Slides, Executive Summary, Financials, Key Metrics, Risiken, Asks. Zwanzig Minuten später hatte er eine Präsentation, die aussah, als hätte sein Team zwei Tage daran gearbeitet. Charts, die auf die Live-Daten im Excel referenzieren. Formatiert in den Farben und Fonts seiner Firma.
Ein Goldman-Sachs-Analyst hat sich das Model angesehen und gesagt: solide. Die Art von Output, für die er selbst einen vollen Tag gebraucht hätte.
Dreißig Minuten. Von einem leeren Spreadsheet zu einer boardfähigen Präsentation.
(Nate B. Jones hat das in seinem Newsletter „I built in 10 minutes what takes a Goldman analyst a day" detailliert beschrieben – mit den Prompts, die er verwendet hat. Leseempfehlung.)
Das ist keine Demo. Das ist ein Produkt, das es heute gibt, für zwanzig Dollar im Monat. Und es wird mit jedem Quartal besser, automatisch, über Nacht, ohne dass jemand ein Update installiert.
Keine Anthropic-Werbung – das Tool heißt nächstes Jahr vermutlich anders. Aber die Frage bleibt: Was passiert mit uns, wenn die Produktion von Wissensarbeit-Artefakten im Preis gegen null geht?
Ich arbeite in der Agentur-Industrie. Ich sehe jeden Tag, wie Organisationen auf diese Verschiebung reagieren – oder nicht reagieren. Plattformen, die hunderte Millionen kosten und Content at Scale versprechen. Teams, die plötzlich in zehn Minuten produzieren, wofür sie letzte Woche drei Tage gebraucht haben. Und eine Frage, die in den meisten Strategiemeetings noch nicht gestellt wird: Wenn das Artefakt nichts mehr kostet – was verkaufen wir dann eigentlich?
Artefakte werden Commodities
Fangen wir mit den Zahlen an.
Die Inference-Kosten für große Sprachmodelle fallen schnell. Epoch AI hat gemessen: Der Preisverfall liegt je nach Performance-Level zwischen Faktor 9 und Faktor 900 pro Jahr. Der Median liegt bei Faktor 50. Andreessen Horowitz nennt den Trend „LLMflation" und beziffert ihn auf Faktor 10 pro Jahr – schneller als der Preisverfall bei Prozessoren während der PC-Revolution, schneller als Bandbreite während des Dotcom-Booms.
Konkret: GPT-4-äquivalente Leistung kostet heute 0,40 Dollar pro Million Tokens. Ende 2022 waren es 20 Dollar. Faktor 50 in drei Jahren.
Tokens kosten Strom. Die Foundation Models sind im Preiskampf. DeepSeek hat den Markt mit 90 Prozent niedrigeren Preisen aufgemischt. OpenAI hat mit 80 Prozent Preissenkung reagiert. Die Richtung ist klar, und sie beschleunigt sich.
Was bedeutet das für die Praxis? Code, Analysen, Präsentationen, Dashboards, Reports – alles, was man als „Output" bezeichnen kann, wird billig. Nicht gratis. Aber die Grenzkosten fallen so schnell, dass die Differenz zu null für die meisten Geschäftsmodelle irrelevant wird.
(Ja, es gibt Gegenargumente. Dazu mehr im Ehrlichkeitstest weiter unten.)
Das ist der Desktop-Publishing-Moment der Wissensarbeit. In den 90ern hat Desktop Publishing plötzlich jedem ermöglicht, Broschüren zu layouten. Hat Grafikdesigner nicht überflüssig gemacht. Aber es hat den Wert fundamental verschoben – weg von der Fähigkeit, ein Layout zu produzieren, hin zur Fähigkeit, ein gutes Layout zu erkennen und in Auftrag zu geben.
Wir stehen an genau diesem Punkt, nur dass es diesmal nicht um Layouts geht, sondern um die gesamte Wissensarbeit. Operating Models. Board Decks. Wettbewerbsanalysen. Due-Diligence-Packs. Pitch Decks. Quartalsberichte. Jedes einzelne Artefakt, das bisher Stunden oder Tage menschlicher Arbeit erfordert hat, kann jetzt in Minuten produziert werden. Nicht in schlechter Qualität. In einer Qualität, die ein Goldman-Analyst „solide" nennt.
Das verändert nicht ein Berufsfeld. Das verändert die Grundlage, auf der Unternehmen Wert schaffen.
Die Pyramide bricht
Wer verstehen will, was das konkret bedeutet, muss sich nur die Consulting-Industrie ansehen.
McKinsey, BCG und Bain haben die Einstiegsgehälter zum dritten Mal in Folge eingefroren. PwC hat die Graduate-Einstellungen 2025 gekürzt. Zwei Senior Executives bei Big-Four-Firmen schätzen, dass die Graduate-Einstellungen bei den größten britischen Beratungsfirmen im kommenden Jahr um die Hälfte sinken werden. Die Harvard Business Review beschreibt den Wandel vom klassischen Pyramiden-Modell zum „Obelisken" – weniger Ebenen, kleinere Teams, AI übernimmt die Arbeit, die früher Junior-Consultants gemacht haben.
Das Pyramiden-Modell der großen Beratungshäuser basiert auf einer simplen Ökonomie: Research, Analyse und Deckbuilding sind teuer, weil sie Arbeitszeit kosten. Viele Junior-Consultants am Boden der Pyramide produzieren Artefakte, die wenige Partner an der Spitze in Judgment verpacken und an Kunden verkaufen. Revenue gleich Zeit mal Expertise.
AI komprimiert die Zeit-Komponente. Ein Analyst-Slot kann durch ein Modell ersetzt werden, das nie schläft und keine Überstunden abrechnet. Die Pyramide wird profitabler – für die Firmen. Denn hier ist die unbequeme Wahrheit: Die Tagessätze sind nicht gefallen. Die Projektgebühren sehen verdächtig vertraut aus. AI hat die Lieferkosten gesenkt, aber die Vorteile bleiben in den P&Ls der Firmen gefangen. Noch.
Namaan Mian, COO von Management Consulted, formuliert es so: Die Fähigkeit, mehr Wert aus weniger Junior-Mitarbeitern zu ziehen, übt Abwärtsdruck auf Vergütung aus. In Professional Services und Tech sei die AI-getriebene Disruption realer als in anderen Sektoren der Wirtschaft.
Was bereits passiert: Neue, AI-native Boutique-Beratungen entstehen, gegründet von ehemaligen Big-Four-Partnern. Mark Bunker, Ex-Deloitte Senior Partner und jetzt Managing Partner bei Queen's Tower Advisory, sagt: Die Basis der Pyramide wird schrumpfen, aber der Bedarf an erfahrenem Urteilsvermögen an der Spitze wird kritischer. Antonio Alvarez von Alvarez & Marsal beschreibt das „Box Model" – eine Struktur, bei der Senior- und Junior-Mitarbeiter zahlenmäßig näher beieinanderliegen als in der klassischen Pyramide.
Die Frage ist nicht ob der Preisdruck bei den Kunden ankommt. Die Frage ist wann. Und wenn er ankommt, bricht nicht nur ein Geschäftsmodell – es bricht ein Paradigma. Denn die Consulting-Pyramide ist nur das sichtbarste Beispiel. Dasselbe Muster gilt für Agenturen, für interne Analyse-Teams, für jede Organisation, deren Wertschöpfung auf der Produktion von Wissensarbeit-Artefakten basiert.
In Deutschland kommt etwas dazu, das in den US-Analysen nicht vorkommt: Betriebsräte. Wenn die Pyramide bricht, ist das ein mitbestimmungspflichtiger Vorgang. Das verlangsamt den Wandel. Aber es erzwingt auch, dass Unternehmen die Verschiebung durchdenken, statt sie einfach passieren zu lassen. Wer einem Betriebsrat erklären muss, warum zwanzig Analyst-Stellen wegfallen und fünf Spec-Stellen entstehen, hat seine Entscheidungsarchitektur dokumentiert. Das ist kein Nachteil. Das ist ein Nebenprodukt, das die meisten US-Firmen nie erzwungen bekommen.
Wenn das Artefakt billig wird, muss der Wert woanders liegen.
Die Frage ist: Wo?
McKinsey hat in seiner State-of-AI-Studie 2025 gemessen, dass die Organisationen mit den besten AI-Ergebnissen nicht die mit den meisten Tools sind. Es sind die, die ihre Workflows fundamental umgestaltet haben und AI als Katalysator für grundlegende Veränderung nutzen, nicht als Beschleuniger für bestehende Prozesse. High Performer investieren mehr als 20 Prozent ihres digitalen Budgets in AI-Technologien und sind dreimal häufiger bereit, individuelle Workflows von Grund auf neu zu denken.
Das bestätigt meine Beobachtung: Der Vorsprung liegt nicht in der Geschwindigkeit der Artefaktproduktion. Er liegt in dem, was die Artefaktproduktion nicht automatisiert – und nie automatisieren wird.
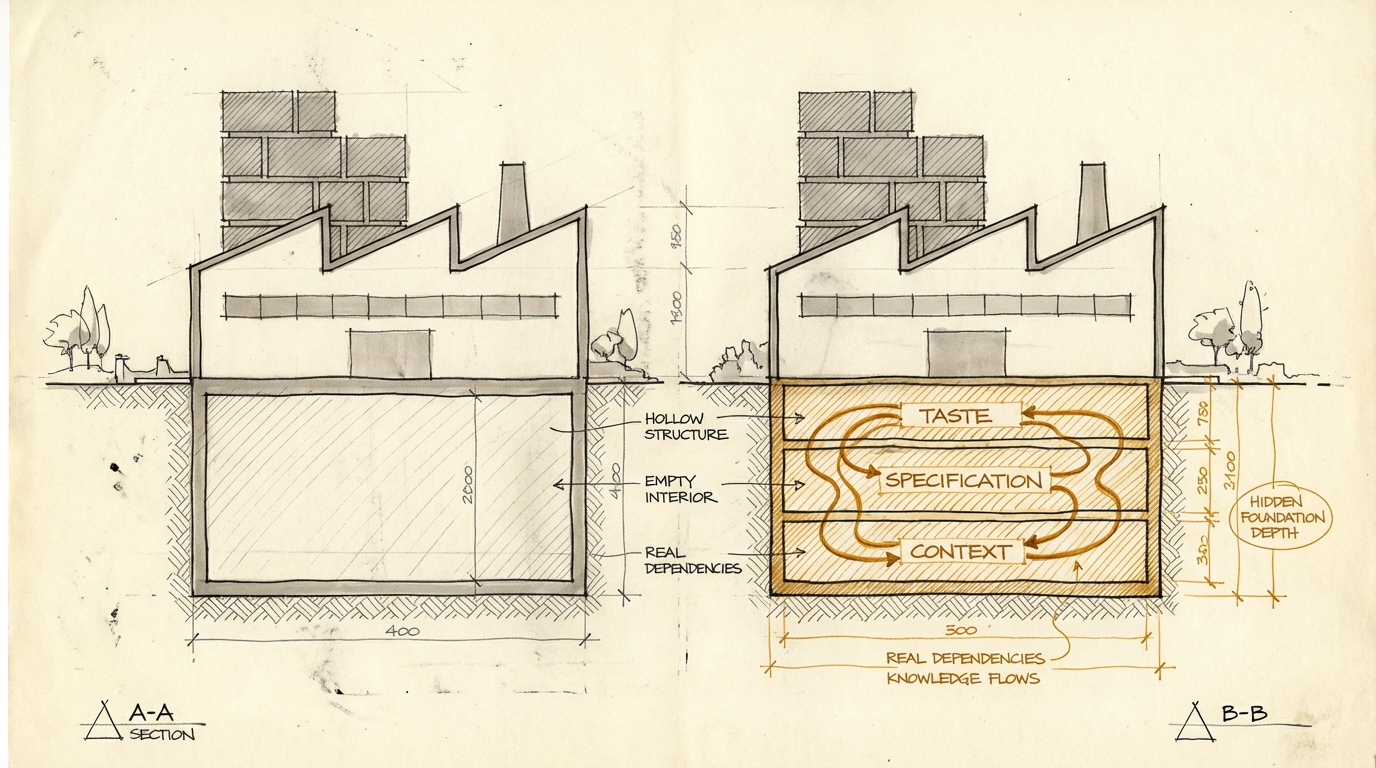
Drei Dinge, die AI nicht billiger macht
Die großen Service-Organisationen investieren in Execution. Plattformen, die Artefakt-Produktion skalieren. Die Frage, die niemand stellt: Wer investiert in das, was wertvoll bleibt?
1. Taste -- wer entscheidet, was gut ist?
Ich meine nicht Geschmack im ästhetischen Sinn. Ich meine Urteilsvermögen. Die Fähigkeit, aus dem Möglichkeitsraum das Richtige auszuwählen.
Wenn Claude fünf technisch korrekte Board-Präsentationen baut – wer entscheidet, welche die richtige Story erzählt? Wenn ein Operating Model drei Szenarien zeigt – wer weiß, welches das Board sehen muss? Wenn eine Analyse zwanzig Datenpunkte liefert – wer erkennt, welche drei die Entscheidung treiben?
Das ist Taste. Es ist die Fähigkeit, die richtige Frage zu stellen, bevor das Modell losläuft. Es ist das Wissen, welches Framing ein Problem braucht. Es ist die Erfahrung zu erkennen, dass eine technisch korrekte Analyse die falsche Frage beantwortet.
Und hier ist das Paradox: Je billiger Artefakte werden, desto wichtiger wird Taste. Weil das Volumen an möglichem Output exponentiell steigt, während die Fähigkeit, Signal von Noise zu unterscheiden, konstant bleibt. Taste ist der einzige Filter. Und er skaliert nicht mit.
Eine Stanford-Studie, veröffentlicht in der Harvard Business Review, hat gemessen, was passiert, wenn er fehlt: 40 Prozent von 1.150 Vollzeit-Beschäftigten hatten bereits AI-generierten „Workslop" von Kollegen erhalten. Technisch kompetent, substanziell leer. Die geschätzten Produktivitätskosten: 186 Dollar pro Mitarbeiter pro Monat in verschwendeter Zeit, die darauf verwendet wurde, professionell aussehenden Output zu verarbeiten, der nichts sagt.
Das Board Deck, das Claude in dreißig Minuten baut, sieht identisch aus. Egal ob jemand eine Stunde über die Strategie nachgedacht hat — oder ob jemand „mach mir ein Board Deck über unsere Q1-Ergebnisse" getippt und sich einen Kaffee geholt hat. Das Format ist sauber. Die Charts stimmen. Das Layout ist professionell. Der Unterschied zwischen den beiden Outputs – zwischen Insight und Slop – ist unsichtbar für das Tool. Er ist nur sichtbar für den Menschen, der entscheidet.
Der Mensch, der sagt: „Stopp. Falsche Vergleichsgruppe. Nochmal, aber mit diesen drei Wettbewerbern." Das ist Taste. Modelle erkennen Muster und reproduzieren sie – aber sie wissen nicht, welche Muster in diesem Kontext relevant sind.
Steve Yegge hat kürzlich ein Framework vorgestellt, das er „Software Survival 3.0" nennt. Sein Argument: Wenn Compute-Ressourcen begrenzt sind, überlebt Software, die Cognition spart. Was absurd teuer wäre, von Grund auf neu zu synthetisieren, bleibt. Was leicht replizierbar ist, wird repliziert und dadurch wertlos.
Er formalisiert das als Survival Ratio: der kognitive Nutzen eines Tools geteilt durch die kognitiven Kosten, es zu kennen und zu benutzen. Tools mit einem Ratio über 1 überleben. Tools darunter werden umgangen.
Übertragen auf Unternehmen: Taste ist Urteilsvermögen, das über Jahre gewachsen ist. Es wäre absurd teuer, es von Grund auf neu aufzubauen. Es entsteht aus Tausenden von Entscheidungen, aus dem akkumulierten Wissen darüber, was in einem spezifischen Markt, für eine spezifische Zielgruppe, in einem spezifischen Kontext funktioniert. Kein Modell kann das replizieren, weil es nie den Kontext hatte. Es kann Artefakte produzieren. Es kann nicht wissen, ob sie die richtigen Artefakte sind.
Die Konsequenz ist unbequem: In Teams, die bisher über Execution definiert waren – wer baut das beste Model, wer macht die saubersten Slides – verschiebt sich der Wert komplett. Execution wird delegiert. Was bleibt, ist die Fähigkeit, vor der Execution die richtige Entscheidung zu treffen. Und nach der Execution den Output kritisch zu bewerten. Das mittlere Drittel – die eigentliche Produktion – wird zum kleinsten Teil des Wertbeitrags.
Aber Taste ist kein Burggraben, hinter dem man sich ausruhen kann. Es ist ein Vorsprung, der verfällt, wenn man ihn nicht pflegt. (Wie schnell er verfällt und warum, dazu mehr im Ehrlichkeitstest weiter unten.)
2. Brand als erlebbare Differenzierung
Wenn jeder dieselben Artefakte produzieren kann – dieselben Slides, dieselben Analysen, dieselben Dashboards – was unterscheidet dann dein Unternehmen vom Wettbewerber?
Die Antwort ist nicht das Logo. Es ist die Erfahrung.
Brand ist, wie sich die Interaktion mit deinem Unternehmen anfühlt. Die Konsistenz. Die Tonalität. Die Art, wie Informationen strukturiert sind. Der Moment, in dem ein Kunde merkt: Das ist anders als bei den anderen. Nicht besser formatiert. Anders gedacht.
Das sieht man schon jetzt. Nehmen wir zwei Agenturen, die dasselbe AI-Tool nutzen, um eine Kampagnenstrategie zu entwickeln. Beide produzieren ein Strategiedeck mit Zielgruppenanalyse, Wettbewerbslandschaft, Kanalempfehlung. Die Artefakte sehen ähnlich aus – weil das Tool ähnliche Artefakte produziert. Was die Kunden unterscheidet, ist nicht das Deck. Es ist die Perspektive, die im Deck steckt.
Es ist der Punkt, an dem eine Agentur sagt: „Wir empfehlen Kanal X, weil wir aus Erfahrung wissen, dass eure Zielgruppe dort anders reagiert als der Markt-Durchschnitt." Das ist Brand im Sinne von: eine erkennbare, erfahrungsbasierte Haltung, die sich nicht kopieren lässt, weil sie aus akkumuliertem Kontext entsteht.
Wenn AI jedem Unternehmen ermöglicht, professionelle Artefakte zu produzieren, wird Professionalität zur Baseline. Sie ist kein Differenzierungsmerkmal mehr. Was differenziert, ist das, was über der Professionalität liegt: die spezifische Perspektive, die spezifische Art, Probleme zu rahmen, die spezifische Haltung, die ein Unternehmen einnimmt.
Das ist kein ästhetisches Argument. Es ist ein ökonomisches. Brand basiert auf akkumuliertem Vertrauen und Wiedererkennung. Beides lässt sich nicht über Nacht aufbauen und nicht kopieren. Wenn Artefakte billig werden, ist das einer der wenigen Differenzierungshebel, der bleibt.
Und Brand muss jetzt expliziter werden. Wenn früher ein Consultant zwei Tage an einem Deck gearbeitet hat, floss Brand implizit ein – durch die Person, ihre Art zu denken, ihre Art zu präsentieren. Wenn jetzt ein Modell das Deck baut, muss Brand als Constraint mitgegeben werden. Design Systems, Tonalitäts-Guidelines, UX-Prinzipien – alles, was bisher implizites Wissen war, muss maschinenkonsumierbar werden. Wer das nicht hat, bekommt generische Artefakte in seinen Firmenfarben. Das ist nicht Brand. Das ist ein Template.
3. Das Datenmodell als Wettbewerbsvorteil
Jedes Unternehmen hat Daten. Kundendaten, Produktdaten, Marktdaten, Transaktionsdaten. Die meisten Unternehmen wissen das. Viele reden davon, dass Daten „das neue Öl" seien. Wenige haben etwas Brauchbares daraus gemacht.
Die Zahlen sind ernüchternd. Nur 6 Prozent der Unternehmen halten ihre Dateninfrastruktur für AI-ready. 71 Prozent der AI-Teams verbringen über ein Viertel ihrer Zeit mit „Data Plumbing" – dem Versuch, chaotische, heterogene, schlecht dokumentierte Daten in eine Form zu bringen, mit der ein Modell etwas anfangen kann. 53 Prozent der Unternehmen, die mit AI-Implementierungen kämpfen, scheitern an unreifen Datensystemen.
Aber die Daten selbst sind nicht der Wert. Der Wert ist das Datenmodell. Also: Wie hat ein Unternehmen seine Domäne verstanden und in Strukturen übersetzt?
Warum gerade jetzt? Weil sich abzeichnet, dass Code selbst zum flüchtigen Zwischenergebnis wird — ein temporärer Cache, der jederzeit aus einer Spezifikation neu generiert werden kann. Wenn Code austauschbar wird, ist das Datenmodell das einzige Software-Artefakt, das dauerhaft Wert hat. Nicht der Code, der darauf operiert. Nicht das Interface, das ihn darstellt. Sondern das Modell der Realität, die das Unternehmen abbilden will.
Ein Datenmodell ist Domänenwissen in Struktur übersetzt. Es sind die Taxonomien, die Relationen, die Schemata, die abbilden, wie ein Unternehmen über seine Kunden, seine Produkte, seinen Markt denkt. Es ist die Antwort auf die Frage: Was sind die Entitäten in unserem Geschäft, und wie hängen sie zusammen?
Klingt abstrakt. Ist es nicht.
Nehmen wir zwei Unternehmen in derselben Branche. Unternehmen A hat seine Kundendaten in einem sauberen Schema: Kundentypen, Segmente, Lifecycle-Phasen, Produktaffinitäten, Interaktionshistorie – alles in einer konsistenten Struktur, mit klaren Definitionen und Relationen. Unternehmen B hat dieselben Daten, aber verteilt über sieben Systeme, mit inkonsistenten Bezeichnungen, ohne dokumentierte Relationen, mit Duplikaten und Lücken.
Jetzt legen beide ein AI-Layer drüber. Unternehmen A gibt dem Modell ein Schema, das in 500 Tokens zu verstehen ist. Das Modell kann sofort sinnvolle Analysen fahren, Muster erkennen, Empfehlungen generieren. Unternehmen B muss dem Modell erst erklären, wo die Daten liegen, was die Felder bedeuten, warum „Kundentyp" in System 3 etwas anderes heißt als in System 5. Das kostet Tausende von Tokens, produziert mehr Fehler und liefert schlechtere Ergebnisse.
Das ist kein technisches Detail. Es ist ein ökonomischer Unterschied. Jeder Token, der für Kontexterklärung draufgeht, ist ein Token, der nicht für Analyse verwendet wird. Token-Effizienz ist die neue Metrik für die Qualität eines Datenmodells. Und Token-Effizienz übersetzt sich direkt in niedrigere Kosten und bessere Outputs.
Steve Yegge nennt das Prinzip „Substrate Efficiency": Manche Berechnungen sind durch LLM-Inference absurd teuer, obwohl sie mit klassischer Software trivial wären.
Dasselbe Prinzip gilt für Unternehmensdaten. Der klügste Ansatz ist nicht, alles durch ein LLM zu jagen – sondern eine Architektur zu bauen, die Berechenbares berechnet und das Modell nur dort einsetzt, wo tatsächlich Interpretation, Synthese oder Urteilsvermögen gebraucht wird.
Das ist eine Architektur-Entscheidung mit strategischen Konsequenzen: Sie bestimmt, wie teuer und wie gut AI-Anwendungen funktionieren. Wer ein token-effizientes Datenmodell hat, zahlt weniger pro Anfrage, bekommt bessere Ergebnisse und kann mehr Anwendungsfälle wirtschaftlich betreiben als der Wettbewerber mit dem Datenchaos.
Databricks und das MIT Technology Review bestätigen das: Wettbewerbsdifferenzierung kommt zunehmend aus den Daten- und Governance-Layern unter der AI, nicht aus dem Modell selbst. Die Organisationen, die echten Fortschritt machen, investieren in semantischen Kontext und eine Architektur, die es Modellen erlaubt, auf vertrauenswürdigen Daten zu operieren.
3M liefert ein konkretes Beispiel: Ihre Daten- und AI-Teams konzentrieren sich darauf, tiefere Metadaten und Businesskontext aufzubauen, bevor sie agentische Fähigkeiten skalieren. Indem sie das semantische Layer hinter ihren Daten stärken, stellen sie sicher, dass jedes Modell und jeder Agent die Klarheit hat, verlässliche Entscheidungen zu treffen. Kontext ist für sie kein technisches Detail – er entscheidet über die Qualität jeder Analyse.
Die Analogie dazu: Das LLM ist der Motor. Das Datenmodell ist die Straße. Ein Formel-1-Motor auf einem Feldweg ist langsam und teuer. Derselbe Motor auf einer Autobahn ist schnell und effizient. Unternehmen investieren gerade Milliarden in bessere Motoren. Fast niemand investiert in die Straße.
Ein gutes Datenmodell zu bauen ist keine Frage von Technologie. Es ist eine Frage von Domänenwissen. Es erfordert, dass jemand versteht, wie das Geschäft funktioniert, und dieses Verständnis in Strukturen übersetzt.
Keine AI kann das für ein Unternehmen tun – sie kennt das Geschäft nicht von innen. Sie kennt Muster aus dem Training, aber nicht den Grund, warum ein bestimmtes Kundensegment in diesem Markt anders funktioniert als in jenem. Dieses Wissen steckt in den Köpfen der Mitarbeiter. Es in ein maschinenkonsumierbares Schema zu übersetzen, ist eine der wertvollsten Investitionen, die ein Unternehmen gerade machen kann.
Gerade der deutsche Mittelstand hat hier einen Vorteil, den er oft nicht sieht. Ein Maschinenbauer in Schwaben, der seit dreißig Jahren Spezialgetriebe baut, hat ein Domänenwissen in den Köpfen seiner Ingenieure, das kein Foundation Model replizieren kann. Die Frage ist, ob er dieses Wissen in ein maschinenlesbares Schema übersetzt -- oder ob es mit den nächsten Pensionierungen verloren geht.
Wo ich falsch liegen könnte
Drei Gegenargumente, die Substanz haben.
Erstens: Reasoning-Modelle treiben die Kosten hoch, nicht runter. Neue Modelle "denken" intern, bevor sie antworten. Mehr Tokens pro Aufgabe, höhere Kosten pro Task. Das stimmt isoliert betrachtet. Aber die Qualität der Ergebnisse steigt mit jedem Modell-Upgrade: weniger Retries, weniger Korrekturen, weniger menschliche Nacharbeit. Der Nettoeffekt auf die Gesamtkosten pro brauchbarem Ergebnis ist fallend. Die Frage ist, wie schnell. Und ob die Modell-Anbieter die Effizienzgewinne an die Kunden weitergeben oder in ihre Margen stecken. Das ist offen.
Zweitens: Taste verfällt schneller als gedacht. Die AI-Baseline steigt mit jedem Modell-Upgrade. Was heute menschliches Urteil erfordert, kann in einem Jahr ein Modell besser. Der Vorsprung durch Taste ist real, aber seine Halbwertszeit ist unklar. In einem Tech-Startup: vielleicht Monate. In der deutschen Industrie mit ihren regulatorischen Eigenheiten: wahrscheinlich Jahre. Wer sich darauf verlässt, dass Taste ein dauerhafter Burggraben ist, ohne ihn aktiv zu schärfen, wird überrascht werden. Taste bleibt wertvoll. Aber nur als Praxis, nicht als Besitzstand.
Drittens: Das Timing. Ich argumentiere, als wäre der Wandel da. Für manche Branchen stimmt das. Für andere ist es noch zwei, drei Jahre weg. Die Consulting-Pyramide bricht nicht morgen -- sie erodiert. Die Frage, ob man jetzt investiert oder abwartet, ist berechtigt. Mein Argument: Die Investition in Taste, Brand und Datenmodell hat auch ohne AI Wert. Man baut keine AI-spezifischen Assets, man baut bessere Entscheidungsarchitekturen. Das lohnt sich so oder so.
Und trotzdem: Die Richtung der Kosten ist eindeutig. Faktor 50 in drei Jahren lässt keinen Interpretationsspielraum. Selbst wenn das Timing um ein, zwei Jahre variiert: Wer wartet, bis die Artefaktproduktion tatsächlich null kostet, hat die Investitionszeit in das verpasst, was dann zählt.
Was Unternehmen jetzt tun sollten
Genug Diagnose. Hier ist, was daraus folgt. Nicht als Fünf-Jahres-Roadmap, sondern als Fragen, die sich jedes Unternehmen stellt, das relevant bleiben will, wenn Artefakte billig werden.
Taste ist Führungsaufgabe
Taste lässt sich nicht delegieren. Es lässt sich nicht an die IT-Abteilung geben, nicht an ein „AI Center of Excellence", nicht an einen Dienstleister. Taste ist das, was Führung vorlebt. Oder nicht.
PwC hat das gemessen: Bottom-Up-Crowdsourcing von AI-Initiativen erzeugt beeindruckende Adoption-Zahlen. Es erzeugt selten brauchbare Ergebnisse.
Drei Konsequenzen.
Führung muss den Qualitätsstandard setzen. Wenn die Geschäftsleitung jeden AI-Output ungeprüft durchwinkt, weil er „professionell aussieht", hat die Organisation kein AI-Problem. Sie hat ein Führungsproblem.
Die wertvollste Entscheidung in einer Welt billiger Artefakte ist „das machen wir nicht". Professionell aussehenden Output killen, weil er die falsche Frage beantwortet — das muss Führung treffen. Als kulturelle Norm, nicht als Kontrollmechanismus.
Die Transformation braucht mehr als Tools. „Macht mal" reicht nicht. Teams brauchen Zeit, Raum und Anleitung, um zu lernen, wann AI-Output gut genug ist und wann nicht. Wann ein Modell die richtige Analyse liefert und wann es eine technisch korrekte Antwort auf die falsche Frage gibt.
Das ist Change Management, nicht IT-Rollout. Es braucht Führungskräfte, die selbst mit den Tools arbeiten, die den Unterschied zwischen Insight und Slop aus eigener Erfahrung kennen — und die bereit sind, das vorzuleben.
Befähigung statt Kontrolle. Es geht nicht darum, AI-Nutzung zu regulieren. Es geht darum, eine Kultur zu schaffen, in der Urteilsvermögen belohnt wird — nicht Outputvolumen.
Das erfordert neue Metriken. Nicht „wie viele Analysen hat das Team produziert?", sondern „welche Entscheidungen hat das Team ermöglicht?". Nicht „wie schnell war der Output?", sondern „hat der Output die richtige Frage beantwortet?".
Wer „weniger, aber richtiger" als Erfolgsmaßstab definieren kann, hat einen kulturellen Vorsprung, der mindestens so viel wert ist wie jede Technologie-Investition.
Framing als Kernkompetenz entwickeln. Die wichtigste Fähigkeit, wenn Artefakte billig werden, ist nicht die Produktion. Es ist das Framing. Welche Frage stellen wir? Welches Problem lösen wir? Für wen? Mit welchem Ziel?
Das lässt sich trainieren. Es lässt sich als Praxis in Meetings, in Briefings, in Projektsetups verankern. Aber nur, wenn Führung es als das behandelt, was es ist: die wertvollste Kompetenz im Unternehmen.
Praktisch bedeutet das: Jedes Briefing beginnt mit der Frage, nicht mit dem Tool. Nicht „lasst uns Claude eine Analyse bauen", sondern „was müssten wir wissen, um diese Entscheidung zu treffen?" Erst wenn die Frage klar ist, kommt die Produktion.
Das klingt trivial. In der Praxis wird es ständig übersprungen, weil die Versuchung groß ist, sofort loszulegen — das Tool ist ja da, der Output kommt in Minuten. Aber zehn Minuten Nachdenken über die richtige Frage sparen Stunden an Artefakt-Produktion, die niemand braucht.
Und es bedeutet auch: Kill-Meetings einführen. Regelmäßige Reviews, in denen nicht gefragt wird „was haben wir produziert?", sondern „was davon hat eine Entscheidung ermöglicht — und was können wir einstellen?"
Wenn Produktion billig ist, ist die Fähigkeit, Dinge nicht zu tun, wertvoller als die Fähigkeit, mehr zu produzieren. Aber diese Fähigkeit entsteht nicht von allein. Sie muss kulturell gewollt, von Führung vorgelebt und strukturell ermöglicht werden.
Das Datenmodell-Audit
Die meisten Unternehmen wissen nicht, in welchem Zustand ihre Daten sind. Drei Fragen, die Klarheit schaffen:
1. Können wir unsere Kernentitäten in einem Satz beschreiben?
„Kunden kaufen Produkte in Kategorien, jeder Kauf hat einen Kanal und einen Zeitpunkt." Das ist ein Datenmodell. Wer stattdessen sagt „das müsste man sich im Detail anschauen", hat Tabellen, aber kein Modell.
2. Wie lange braucht ein neuer Analyst, um unsere Daten zu verstehen?
Drei Monate? Dann braucht ein LLM dieselbe Kontextmenge. Nur bezahlt es sie in Tokens, nicht in Monaten. Und das wird teuer, bei jeder einzelnen Anfrage.
3. Wie token-effizient ist unser Schema?
Kann ein LLM unsere Datenstruktur in 500 Tokens verstehen — oder braucht es 50.000? Ein Schema, das sich in wenigen Sätzen erklären lässt, produziert bessere Ergebnisse bei niedrigeren Kosten. Das ist kein technisches Kriterium. Es ist ein strategisches.
Der Test: Setz dich mit jemandem aus deinem Data-Team zusammen und versuch, euer Datenmodell in fünf Sätzen zu erklären. Wenn es geht, habt ihr ein Modell. Wenn nicht — dann habt ihr ein Problem, das mit jedem AI-Anwendungsfall teurer wird.
Nicht alles muss durch ein LLM laufen
Wer akzeptiert, dass Inference Strom kostet und Strom endlich ist, kommt zu einer klaren Konsequenz: Nicht alles sollte durch ein LLM laufen. Die Frage ist: Was braucht tatsächlich Reasoning – und was lässt sich mit klassischer Software lösen?
Das Prinzip: Berechenbares berechnen. Wiederkehrende Anfragen cachen. Strukturierte Daten so zugänglich machen, dass das Modell gezielt zugreift statt den gesamten Kontext zu durchsuchen. Und das LLM nur dort einsetzen, wo tatsächlich Interpretation, Synthese oder kreative Verknüpfung gebraucht wird.
Die Frage für Unternehmen: Was sind die Textsuchen eures Geschäfts — die Routineaufgaben, die heute durch ein Sprachmodell laufen, obwohl klassische Software sie schneller und billiger löst? Yegges Substrate-Efficiency-Prinzip (siehe Datenmodell-Sektion) gilt hier genauso: Jeder Token, der nicht durch Inference fließen muss, ist gesparte Kosten.
Das klingt nach IT-Architektur. Ist es auch. Aber es ist die Art von Architektur-Entscheidung, die bestimmt, ob ein Unternehmen AI wirtschaftlich betreiben kann – oder nach dem Pilotprojekt feststellt, dass die Kosten das Budget sprengen.
Brand muss maschinenlesbar werden
Die implizit-zu-explizit-Verschiebung aus der Brand-Sektion hat eine praktische Konsequenz: Wer Brand als Constraint mitgeben will, braucht mehr als Farben und Fonts.
Ein konkretes Beispiel: „Das wichtigste Argument steht immer auf Slide 2, nicht auf Slide 5." „Nie mehr als drei Kennzahlen pro Slide." „Charts haben immer eine Handlungsempfehlung als Untertitel, nie nur eine Beschreibung." Das sind Regeln, die sich einem Modell mitgeben lassen. Und sie erzeugen Outputs, die sich anfühlen wie die Firma — nicht wie ein generisches AI-Ergebnis in Firmenfarben.
Die Frage ist nicht technisch, sondern intellektuell: Was macht unsere Art zu kommunizieren spezifisch? Und lässt sich das in Regeln übersetzen, die ein Modell anwenden kann? Wer diese Arbeit nicht macht, überlässt die Brand-Konsistenz dem Default-Verhalten eines Foundation Models, das für alle Kunden gleich agiert.
Die asymmetrische Zukunft
Ein letzter Gedanke.
Die Tools werden mit jedem Quartal besser. Automatisch. Über Nacht. Ohne dass jemand etwas tut. Ein neues Modell wird ausgerollt, und jede Installation auf der Welt wird über Nacht schlauer. Das Operating Model, das letzte Woche zehn Minuten gebraucht hat, wird nächstes Quartal vielleicht fünf brauchen. Die Qualität wird steigen. Die Kosten werden fallen. Das ist die eine Seite.
Taste wird nicht automatisch besser. Brand baut sich nicht über Nacht auf. Ein Datenmodell entsteht nicht durch ein Modell-Upgrade. Diese drei Assets werden nur besser, wenn Menschen daran arbeiten. Bewusst, über Zeit, mit Urteilsvermögen.
Das eine skaliert von allein. Das andere nicht. Und genau deshalb ist es wertvoll.
Die Plattformen, die gerade Artefakt-Produktion skalieren, sind nicht falsch. Die Effizienzgewinne sind real. Aber sie kommen bei allen an. Jeder Wettbewerber hat Zugang zu denselben Foundation Models, denselben Inference-Kosten, derselben Produktionsgeschwindigkeit. Die Plattform ist kein Wettbewerbsvorteil. Sie ist die neue Baseline.
Die Unternehmen, die stattdessen – oder zusätzlich – in Taste, Brand und ihr Datenmodell investieren, bauen an etwas, das mit jedem Modell-Upgrade wertvoller wird, nicht billiger. Denn je besser die Modelle werden, desto mehr Artefakte können desto mehr Menschen produzieren. Und desto mehr kommt es darauf an, wer die richtigen Fragen stellt, wer eine wiedererkennbare Perspektive hat und wessen Daten so strukturiert sind, dass die Modelle tatsächlich etwas damit anfangen können.
Wer in Artefaktproduktion investiert, kauft sich Zeit. Wer in Taste, Brand und Datenmodell investiert, baut sich eine Position.
Artefaktproduktion just got cheap. Der Wettbewerb hat gerade erst angefangen.
Quellen und weiterführende Links
Primäre Referenzen:
- Nate B. Jones: „I built in 10 minutes what takes a Goldman analyst a day + the 4 prompts to do it yourself" (Februar 2025) – Das Operating-Model-Beispiel und die Analyse zu Claude in Excel/PowerPoint
- Steve Yegge: „Software Survival 3.0" (Januar 2026) – Das Survival-Ratio-Framework, Substrate Efficiency und die Cognition-Spar-These
Inference-Kosten und LLMflation:
- Epoch AI: „LLM inference prices have fallen rapidly but unequally across tasks" (März 2025) – Preisverfall zwischen Faktor 9 und 900 pro Jahr, Median 50x — epoch.ai
- Andreessen Horowitz: „Welcome to LLMflation" (November 2024) – Faktor 10 pro Jahr, schneller als Moore's Law und Edholm's Law — a16z.com
- Introl: „Inference Unit Economics: The True Cost Per Million Tokens" (Februar 2026) – GPT-4-äquivalent: $0,40/M Tokens vs. $20 Ende 2022 — introl.com
Consulting-Industrie:
- Slashdot / Financial Times: „Top Consultancies Freeze Starting Salaries as AI Threatens Pyramid Model" (Dezember 2025) – McKinsey, BCG, Bain frieren Einstiegsgehälter zum dritten Mal ein; PwC kürzt Graduate-Einstellungen — tech.slashdot.org
- Harvard Business Review: „AI Is Changing the Structure of Consulting Firms" (September 2025) – Vom Pyramiden- zum Obelisk-Modell — hbr.org
- ConsultingQuest: „How AI Is Changing Consulting Economics" (November 2025) – Productivity Paradox: Kosten sinken, Preise bleiben — consultingquest.com
Dateninfrastruktur und AI-Readiness:
- CData / BetaNews: „Just six percent of enterprises believe their data infrastructure is AI ready" (Dezember 2025) – 6% AI-ready, 71% Data Plumbing — betanews.com
- Databricks / MIT Technology Review: „Infrastructure & Strategies Driving the Next Wave of Enterprise AI" (2025) – Wettbewerbsdifferenzierung aus Daten- und Governance-Layern — databricks.com
AI-Strategie und Organisationen:
- McKinsey: „The state of AI in 2025" (November 2025) – High Performer redesignen Workflows, investieren >20% Digital-Budget in AI — mckinsey.com
- PwC: „2026 AI Business Predictions" (2025) – Top-Down-Programme vs. Crowdsourcing; Hourglass-Modell der Workforce — pwc.com
Workslop-Studie:
- Stanford / BetterUp, veröffentlicht in Harvard Business Review – 40% haben AI-generierten Workslop erhalten; $186/Monat Produktivitätskosten pro Mitarbeiter
Praktischer Test zum Essay
Drei Vorlagen für ein Gespräch mit einer KI: Ziel klären, Widersprüche prüfen, Delegierbarkeit testen. Du bekommst keine fertige Strategie und keine Tool-Empfehlung.
Vorlagen öffnen