Executive Briefing: Der unsichtbare Input
Was zwischen eurem AI-Business-Case und einem Edelgas am Persischen Golf steht
Praktischer Test zum Essay
Drei Vorlagen für ein Gespräch mit einer KI: Ziel klären, Widersprüche prüfen, Delegierbarkeit testen. Du bekommst keine fertige Strategie und keine Tool-Empfehlung.
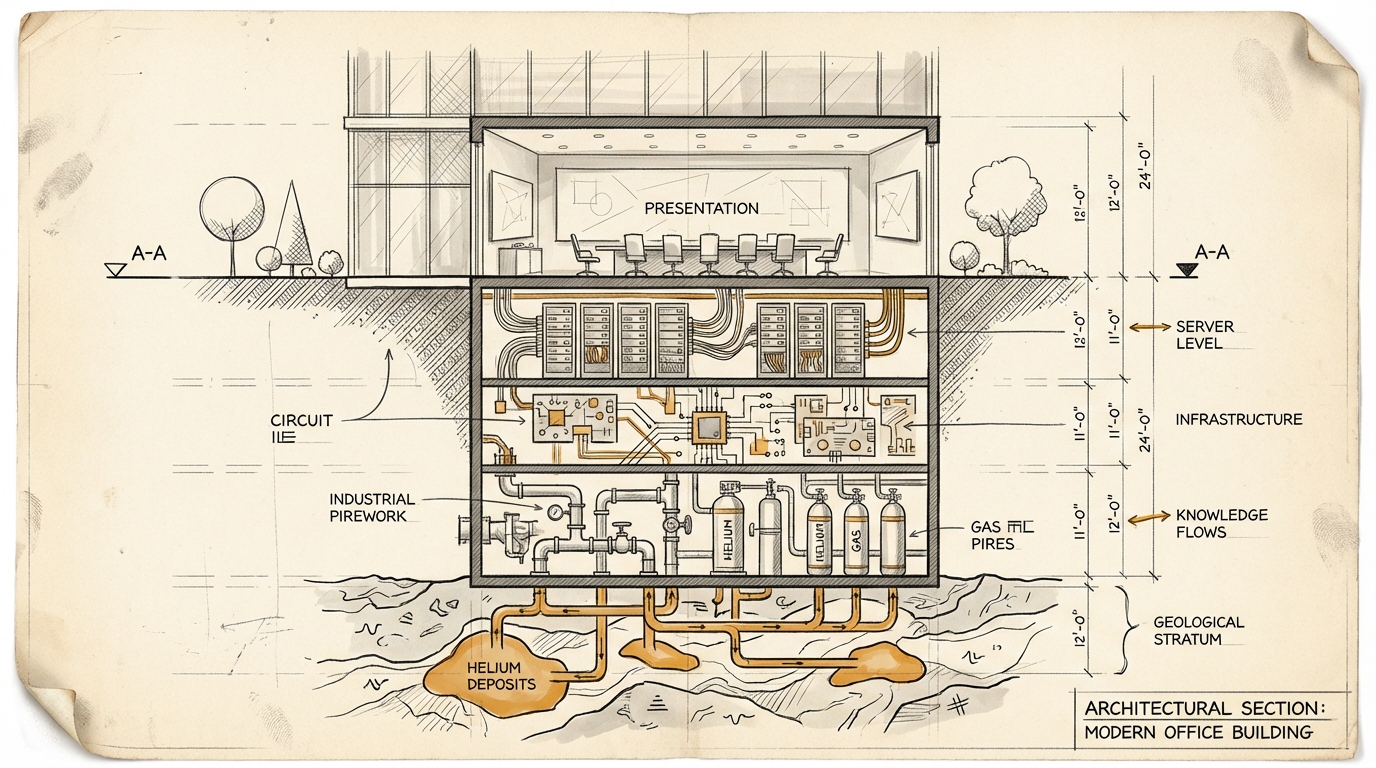
Vorlagen öffnenHelium ist ein Edelgas. Es kühlt Supraleiter in MRT-Geräten. Es spült die optischen Kammern der EUV-Lithografie-Maschinen, ohne die keine modernen Chips gefertigt werden können. Ohne Helium keine Chips. Ohne Chips keine Server. Ohne Server kein AI-Compute.
Bleib auf dem Laufenden
Erhalte eine Nachricht, wenn ein neuer Essay erscheint. Jederzeit abbestellbar.
Eine Anlage in Qatar hat ein Drittel der Weltproduktion geliefert. Seit dem 4. März steht sie still.
In keinem einzigen AI-Business-Case, den ich in den letzten sechs Monaten gesehen habe, steht das Wort "Helium."
Warum ein Sonderbriefing
dekodiert erscheint regulär alle zwei Wochen. Dieses Briefing kommt außer der Reihe, weil sich das Terrain verschoben hat. Nicht irgendein Terrain. Das Terrain, auf dem jede AI-Investitionsentscheidung der letzten zwei Jahre gebaut wurde.
Die Annahme war: Compute wird billiger und verfügbarer. Die $420 Milliarden, die Hyperscaler allein für 2026 an Capex committed haben, basieren darauf. Eure AI-Roadmap basiert darauf. ob ihr es wisst oder nicht. Meine Empfehlungen in früheren Ausgaben basieren darauf.
Seit dem 28. Februar 2026 stimmt diese Annahme nicht mehr ohne Weiteres. Die Auswirkungen sind jetzt besser absehbar.
Das hier ist keine Panik. Es ist eine Terrainanalyse. Was sich verändert hat, was das bedeutet, und was ihr jetzt prüfen solltet.
Die Kette
Am 28. Februar haben die USA und Israel militärische Schläge gegen den Iran durchgeführt. Iran hat mit Gegenschlägen geantwortet, unter anderem gegen Qatars Ras Laffan Industrial City. Ras Laffan ist der weltgrößte LNG-Exporthub und der Standort, an dem rund ein Drittel des globalen Heliums als Nebenprodukt der Erdgasverarbeitung gewonnen wird. QatarEnergy hat am 4. März Force Majeure auf alle betroffenen Verträge erklärt. Die Straße von Hormuz ist für westlich-alliierte Handelsschifffahrt faktisch geschlossen.
Am 18. und 19. März wurde der Komplex erneut getroffen. 14% der Produktionskapazität sind laut QatarEnergy permanent beschädigt, Wiederaufbau: drei bis fünf Jahre. Der Rest steht still, bis die Kampfhandlungen enden.
Das klingt nach einem geopolitischen Problem am Persischen Golf. Es ist ein Compute-Problem in Frankfurt, Dublin und Ashburn, Virginia.
Die Transmissionskette: Helium fällt aus → EUV-Lithografie-Maschinen können nicht betrieben werden → Chip-Produktion verlangsamt sich → Memory-Preise steigen (DRAM bereits +170%, DDR5 vervierfacht) → Server werden teurer und knapper → Cloud-Kapazität wird rationiert oder verteuert → AI-Workloads werden teurer → euer Business Case stimmt nicht mehr.
Gleichzeitig: Brent bei $126, europäische LNG-Preise verdoppelt. Die Datacenter, die noch laufen, kosten mehr im Betrieb.
Nicht eine Krise. Multiple Krisen. Gleichzeitig.
Die stille Prämisse
Jeder AI-Business-Case der letzten zwei Jahre hat eine Zeile "Compute-Kosten" mit einem impliziten Pfeil nach unten. Niemand hat das Szenario "Compute wird teurer" modelliert. Das ist keine Schande. Die gesamte Branche hat das nicht getan.
Aber es zeigt etwas über die Art, wie wir AI-Investitionen planen: Wir planen auf der Oberfläche des Stacks. Cloud-Provider, API-Kosten, GPU-Instanztypen. Die physische Kette darunter ist unsichtbar. Welcher Chip, aus welcher Fab, mit welchem Rohstoff, aus welcher Region. Sechs Glieder von eurem API-Call bis zum Persischen Golf, und kein Entscheider hatte die Kette auf dem Schirm.
In Text #4 ging es um Branchen, die für AI-Agenten nicht existieren, weil sie keine API haben. Helium ist die nächste Ebene: eine Branche, die für die meisten Menschen nicht existiert. Kaum ein Director-Level-Entscheider in DACH denkt über Helium nach. Aber Helium bestimmt, ob die Hardware geliefert wird, auf der seine AI-Strategie aufsetzt.
Die unsichtbare Ökonomie hat eine physische Schicht. Und die ist gerade gerissen.
Drei Brennpunkte
Statt einer abstrakten Branchenanalyse: drei konkrete Perspektiven, die zeigen, wie unterschiedlich die Kette wirkt, aber wie ähnlich das Muster ist.
Ein MRT-Scanner in einem deutschen Krankenhaus
Ein konventioneller MRT-Scanner braucht bei Erstbefüllung 1.500 bis 2.000 Liter flüssiges Helium für die Supraleiter-Kühlung. In Deutschland sind rund 3.200 MRT-Geräte installiert (Deutsche Krankenhausgesellschaft, 2025). Wenn 10% davon ausfallen, weil nach einem Quench kein Helium für die Neubefüllung verfügbar ist, fehlen 8.000 Untersuchungen pro Tag. Zwei Millionen im Jahr. Verzögerte Krebsdiagnosen. Verschobene OP-Planungen.
Das ist die direkte Helium-Abhängigkeit. Dazu kommt die indirekte: Die Chips im MRT-Scanner brauchen Helium für die Fertigung. Die AI-Diagnostik, die auf dem Scanner aufbaut, braucht GPU-Compute, der auf Chips läuft, die Helium brauchen. Dreifache Kette, dreifache Verwundbarkeit.
Heliumfreie Hochfeld-MRT-Systeme (3 Tesla, der klinische Standard) sind laut Fraunhofer IPA frühestens 2031 realistisch. Siemens Healthineers hat mit BlueSeal einen Ansatz, der nur 7 Liter braucht statt 1.500, aber der funktioniert bisher nur bei Niedrigfeld-Systemen. Für die installierte Basis und die Hochfeld-Diagnostik gibt es auf drei bis fünf Jahre keine Alternative.
Das MedTech-Beispiel zeigt die Kaskade am greifbarsten: vom Edelgas bis zur Krebsdiagnose in drei Schritten.
Eine Halbleiterfab in Dresden
In einer 300mm-Fab werden täglich 2.000 bis 3.000 Liter gasförmiges Helium verbraucht. Für Lecktests (kein anderes Gas liefert die Empfindlichkeit), für Backside Cooling in Etch-Anlagen (ohne Helium driftet die Wafer-Temperatur, Yield-Einbruch 15 bis 25%), für CVD-Prozesse als Trägergas.
Der Bulk-Tank fasst 8.000 Liter. Reicht für zehn bis zwölf Tage. Recycling-Infrastruktur: bisher eher selten vorhanden. Warum nicht? Weil Helium bisher billig genug war, dass sich die Investition nicht rechnete. Ein Recovery-System kostet 2 bis 4 Millionen Euro. Bei den alten Preisen lag der ROI jenseits von fünf Jahren. Beim heutigen Spotpreis unter einem Jahr. Aber die Installation dauert zwölf bis achtzehn Monate.
Das ist der Unterschied zwischen Leading Edge und Mature Node, der in der öffentlichen Debatte oft durcheinander geworfen wird. EUV-Scanner verbrauchen 1.500 bis 2.500 Liter Helium pro Stunde. Eine Fab mit zehn EUV-Scannern braucht Dimensionen mehr als eine DUV-Fab. Deutsche Fabs (Infineon Dresden, Bosch Reutlingen) produzieren auf Mature Nodes (28nm und größer) und sind betroffen, aber kurzfristig nicht existenzbedrohend. Langfristig ist das anders.
Denn: Die Amur Gas Processing Plant in Russland (Gazprom) hat eine geplante Helium-Kapazität von 60 Millionen Kubikmetern pro Jahr. Das sind 37% der bisherigen Weltproduktion. Dieses Helium geht nach China. Nicht nach Europa. SMIC baut parallel drei neue Fabs für Mature-Node-Chips. Mit russischem Helium, mit Industriestrom zu 40 bis 50% unter europäischem Niveau, mit staatlichen Subventionen.
Ein Brancheninsider formuliert es so: "Europa investiert 43 Milliarden in Fab-Kapazität und vergisst, die Versorgung mit den Materialien sicherzustellen, die man braucht, um diese Fabs zu betreiben. Das ist, als würde man eine Autobahn bauen und vergessen, Tankstellen zu planen." (SEMI Fab Forecast, BGR DERA Rohstoffinformationen Nr. 40, Silicon Saxony)
Ein Handelskonzern mit 47 Millionen AI-Investment
Cloud-Kosten bei 3,2 Millionen Euro im Monat. GPU-Spot-Verfügbarkeit für Training: minus 60 bis 70% seit dem 28. Februar. Die Personalisierungs-Engine generiert 4,2% Uplift auf den Warenkorbwert, bei 2,3 Milliarden Online-Umsatz sind das real circa 58 bis 65 Millionen Euro. Der Business Case war solide.
Jetzt die doppelte Schere: Compute-Kosten steigen (Gartner: +8 bis 12% für Public Cloud in Europa), und gleichzeitig sinkt der Kuchen, auf den der Uplift angewendet wird (ifo Institut: Inflationsprognose auf 3,8% angehoben, GfK: Konsumstimmung minus 8 bis 12 Punkte für Q3).
Dazu: Temu und Shein operieren mit strukturell niedrigeren Infrastrukturkosten. Inländische Cloud, eigene Chip-Produktion, subventionierte Energie. Wenn eure Compute-Kosten steigen und ihre nicht, verschiebt sich der Wettbewerbsvorteil weiter.
Der CDO eines großen deutschen Handelskonzerns fasst es in einem Satz zusammen: "Wir haben unsere gesamte Digitalstrategie auf die Annahme gebaut, dass Compute-Kosten weiter sinken. Niemand hat 'Compute wird teurer' modelliert."
Die eigentliche Verschiebung
Was die drei Brennpunkte verbinden: Es geht nicht um Helium. Es geht um die Architektur des Systems.
Charles Perrow hat 1984 in "Normal Accidents" beschrieben, warum bestimmte Systeme unvermeidlich Kaskaden produzieren. Nicht weil Menschen versagen, sondern weil die Systemarchitektur Kaskaden erzwingt. Sein Kriterium: Systeme, die gleichzeitig komplex UND eng gekoppelt sind. Kernkraftwerke. Petrochemie. Und, wenn man die Kette durchgeht: die globale AI-Infrastruktur.
Eng gekoppelt: Jedes Glied hängt direkt am vorherigen. Helium fällt aus, Chips werden knapp, Server werden knapper, Cloud wird teurer, euer Business Case kippt. Kein Puffer dazwischen. Fab-Vorräte: eine Woche.
Komplex: Energie beeinflusst Fabs UND Cloud gleichzeitig. Geopolitik beeinflusst Helium UND Öl UND Schifffahrtsrouten gleichzeitig. Memory-Preise beeinflussen Server UND Embedded Systems UND Smartphones gleichzeitig. Die Wechselwirkungen sind nicht linear, nicht vorhersehbar, und in keinem Risikomodell korrekt abgebildet.
Die Rückversicherungsbranche sieht das am klarsten, weil es ihr Geschäft ist, genau solche Korrelationen zu modellieren. Und die Botschaft von dort ist unbequem: Die Korrelationsmatrix, die europäische Versicherer für ihre Portfolios verwenden, ist für dieses Szenario nicht kalibriert. Branchen, die als unabhängig gelten (Automotive, Medizintechnik, Energie, Handel, Finanzen), sind alle über dieselbe Halbleiter-Lieferkette verbunden.
$420 Milliarden committed Hyperscaler-Capex. Ein Drittel des Heliums weg. Die Frage der Rückversicherer: Wer trägt das Risiko? Ihre Antwort: Im Moment niemand. Nicht bewusst.
Ehrlichkeitstest
Vier Punkte, an denen diese Analyse falsch sein könnte.
Erstens: Ein Ceasefire könnte schnell kommen. Wenn die Kampfhandlungen in Wochen enden, normalisiert sich die Versorgung in Monaten. Aber: 14% der Kapazität sind permanent beschädigt. Selbst im Best Case bleibt die Erkenntnis: Die Infrastruktur hängt an einem Faden. Und die nächste Disruption wird an einer anderen Stelle kommen.
Zweitens: Technologie-Kompression könnte helfen. Google TurboQuant reduziert den Memory-Bedarf für Inferenz um 70%. Quantisierte Modelle, Modell-Destillation, effizientere Architekturen. Das ist real und relevant. Aber: Diese Technologien profitieren primär Unternehmen, die bereits at scale operieren. Für den Mittelstand, der gerade erst anfängt, sind sie eine Option, aber kein Rettungsanker.
Drittens: Deutsche Unternehmen sind weniger cloud-abhängig als amerikanische. Viele DACH-Unternehmen betreiben eigene Rechenzentren. Die Cloud-Kosten-Exposition ist real, aber nicht für alle gleich. Allerdings: Der Energiekosteneffekt trifft alle. Und die Hardware für eigene Rechenzentren wird genauso knapper und teurer.
Viertens: Dieses Thema könnte zu weit von AI-Transformation entfernt sein. Helium-Geopolitik ist nicht das, wofür ihr dekodiert lest. Aber genau das ist der Punkt: TERRAIN kennen heißt, die Constraints zu kennen, auf denen die Strategie aufbaut. Wer sein Terrain nicht kennt, investiert blind. Und dieser Constraint hat sich gerade fundamental verschoben.
Was ihr jetzt prüfen solltet
Nicht: "Stoppt alles." Das wäre die Panik-Reaktion, und Panik ist genauso falsch wie Ignoranz.
1. Business Cases auf Robustheit testen. Welche Compute-Kosten-Annahmen stecken in eurem AI-Business-Case? Lauft ihn mit +30%, +50% und +80% durch. Welche Projekte überleben alle drei Szenarien? Das sind die, die weiterlaufen sollten. Die anderen brauchen einen Plan B.
2. Von Expansion zu Allokation umschalten. Wenn Compute knapper und teurer wird, verschiebt sich die Frage von "Welche AI-Projekte starten wir?" zu "Welche Projekte sind die Compute-Kosten wert?" Das ist ein Taste/Evaluation-Problem. Priorisieren statt demokratisieren. Die fünf Use Cases mit dem besten Return pro Compute-Euro ausbauen, den Rest pausieren.
3. Die Kette sichtbar machen. Welcher Cloud-Provider? Welche GPU? Welcher Chip? Welche Fab? Welche Region? Welcher Rohstoff? Die meisten von euch kennen die ersten zwei Glieder. Die anderen vier sind das Terrain, das sich gerade verschoben hat. Es reicht nicht, den API-Call zu kennen. Ihr müsst die Kette kennen.
4. Lokal neu bewerten. Edge Computing, On-Premise-Inferenz, quantisierte Modelle. Wenn Cloud teurer wird, wird lokal relativ attraktiver. Für DACH mit seiner Datenschutz-Sensibilität könnte das ein struktureller Vorteil sein. Aber: Die Hardware dafür ist genauso von der Lieferkette abhängig. Wer bestellen will, sollte es jetzt tun, nicht in drei Monaten.
5. Energie und Compute zusammen denken. AI-Compute ist Energieverbrauch. Energiekosten steigen. Wer seine AI-Strategie von seiner Energiestrategie trennt, hat zwei Strategien, die sich gegenseitig nicht kennen. Das ist ein Luxus, den sich gerade niemand leisten kann.
dekodiert selbstgemacht
Drei Denkwerkzeuge zu diesem Briefing. Kopieren, in die KI eurer Wahl einfügen, und im Gespräch eure eigene Situation durchleuchten. Details und die vollständigen Prompts findet ihr auf dekodiert.de.
Prompt 1: Der Ketten-Finder. Lass die KI die physischen Abhängigkeiten eurer AI-Strategie aufdecken. Von der Cloud-Rechnung zurück zu den Atomen. Am Ende wisst ihr, welche Glieder der Kette euer gesamtes AI-Portfolio tragen.
Prompt 2: Der Business-Case-Stresstest. Nimm einen konkreten AI-Business-Case und lass ihn unter drei Szenarien laufen: +30%, +50%, +80% Compute-Kosten. Nicht ob AI funktioniert, sondern ob die Ökonomie noch stimmt.
Prompt 3: Der Perrow-Test. Wo ist euer System komplex UND eng gekoppelt? Wo erzeugt ein einzelner Ausfall Kaskaden, die nicht im Monitoring auftauchen? Die spannendsten Kopplungen sind die zwischen Systemen, die in unterschiedlichen Abteilungen verantwortet werden.
Einordnung
Dieses Briefing ist ein Sonderbriefing. Es kommt außer der Reihe, weil das Thema zeitkritisch ist. Die regulären Ausgaben von dekodiert erscheinen weiterhin im gewohnten Rhythmus.
In den bisherigen Texten habe ich argumentiert, dass AI den Wert von der Produktion zur Steuerung verschiebt. Dass Specification und Evaluation die Engpässe sind. Dass der maschinenlesbare Kontext die Voraussetzung ist. Dass billigere Execution mehr Ambition profitabel macht, nicht weniger.
Nichts davon ist falsch geworden. Aber alles davon hat eine Randbedingung bekommen, die vorher unsichtbar war: Die physische Infrastruktur, auf der AI läuft, ist fragiler als angenommen. Und sie hat gerade einen Stresstest bekommen, den niemand eingeplant hatte.
Die Frage ist nicht, ob AI funktioniert. Die Frage ist, was sie kostet, wer sich das leisten kann, und wie lange die Infrastruktur braucht, um zu liefern.
Wer das in seinem nächsten Board-Meeting nicht adressiert, hat das Terrain nicht verstanden.
Quellen: Gasworld, CNBC, Fortune, C&EN, Fitch Ratings, IDC, USGS, IEA, SEMI World Fab Forecast, BGR DERA Rohstoffinformationen Nr. 40, BVMed, ZVEI, Fraunhofer IPA/IPMS, DKG, OECD Health Statistics, Silicon Saxony, ifo Institut, Gartner IT Spending Forecast, GfK Consumer Climate, VDA, Gazprom/Neftegaz.ru, Swiss Re sigma, Lloyd's Systemic Risk Scenarios. Vollständige Quellenübersicht auf dekodiert.de.
Dieses Briefing basiert auf einem Board Research Package mit 18 benannten Primärquellen, ergänzt durch eine DACH-spezifische Analyse aus sechs Industrie-Perspektiven (Automotive, MedTech, Halbleiter, Beratung, Versicherung, Handel) mit jeweils eigener Quellenarbeit.
Praktischer Test zum Essay
Drei Vorlagen für ein Gespräch mit einer KI: Ziel klären, Widersprüche prüfen, Delegierbarkeit testen. Du bekommst keine fertige Strategie und keine Tool-Empfehlung.
Vorlagen öffnen