Evaluation ist die neue Führungsarbeit
Ein Unternehmen zeigt stolz seine AI-KPIs. Hohe Adoption. Sinkende Bearbeitungszeit. Mehr Output pro Kopf. Die Kosten pro Vorgang fallen. Alles bewegt sich in die richtige Richtung, jedenfalls wenn man auf die Bewegung schaut.
Praktischer Test zum Essay
Drei Vorlagen für ein Gespräch mit einer KI: Ziel klären, Widersprüche prüfen, Delegierbarkeit testen. Du bekommst keine fertige Strategie und keine Tool-Empfehlung.
Vorlagen öffnenInteressant wird es, wenn ich frage: Beweist das gerade Wertschöpfung, oder zeigt es nur Aktivität?
Genau dort kippt das Thema. Viele Organisationen messen sehr ordentlich, wie stark sich ihr System bewegt. Sie messen nur erstaunlich unsauber, ob es sich in die richtige Richtung bewegt. Nicht, weil sie keine Daten hätten. Sondern weil sie Kontrolle mit Evaluation verwechseln. Sie bauen Dashboards, Kennzahlen, Freigaben und Review-Schritte. Aber es fehlt die Schicht darüber, die prüft, ob dieser ganze Steuerungsapparat überhaupt das Richtige misst.
Genau deshalb wird Evaluation in einer Welt billiger Execution von einer Qualitätsfrage zu einer Führungsfrage.
Praktischer Test: Wenn ihr eure eigene Prüflogik testen wollt: Die drei Vorlagen zum Essay führen durch KPI-Stresstest, Prüfung der Review-Kapazität und Audit-Fragen. Ihr bekommt kein neues KPI-Framework und keine Toolliste, sondern bessere Fragen dazu, ob eure Steuerung Wahrheit oder nur Aktivität misst.
Bleib auf dem Laufenden
Erhalte eine Nachricht, wenn ein neuer Essay erscheint. Jederzeit abbestellbar.
Wir reden bei AI gern über Modelle, Tools und Prozesse. Weniger gern reden wir darüber, dass der Engpass nach billiger Ausführung nicht automatisch in noch besseren Prompts liegt, sondern in etwas Langsamerem, Knappem und politisch Unbequemerem: Urteil.
Wer prüft, ob ein Ergebnis gut genug ist? Wer merkt, dass eine Kennzahl längst zum Proxy geworden ist? Wer hält dagegen, wenn alles effizienter aussieht, aber die Organisation gerade lernt, in die falsche Richtung sauberer zu arbeiten?
Das ist keine Nebenfrage. Das ist die neue Führungsarbeit.
Kontrolle ist nicht Evaluation
AI-Kontrolle sieht professionell aus. Sie hat Dashboards. Nutzungszahlen. Token-Kosten. Automatisierungsraten. Review-Prozesse. Freigabestufen. Eskalationspfade. Das Problem ist nur: Vieles davon misst zunächst, dass etwas läuft. Nicht, dass es stimmt.
Eine Organisation kann ausgezeichnet kontrolliert und gleichzeitig schlecht evaluiert sein.
Dann weiß sie vielleicht:
- wie oft ein Tool genutzt wurde
- wie schnell ein Vorgang bearbeitet wurde
- wie viele Outputs erzeugt wurden
- welche Kosten eingespart wurden
Sie weiß aber nicht sauber genug:
- ob der Output inhaltlich besser geworden ist
- ob das System auf das richtige Ziel optimiert
- unter welchen Bedingungen es systematisch irrt
- wo die menschliche Review-Kapazität längst nicht mehr mithält
- welche Kennzahl nur noch beruhigt, statt etwas zu erklären
Kontrolle fragt: Läuft das System? Evaluation fragt: Läuft es in die richtige Richtung, und woran würden wir merken, dass es das nicht tut?
Das ist ein größerer Unterschied, als viele Dashboards vermuten lassen.
Der neue Engpass heißt Urteilskapazität
Solange Ausführung teuer war, ließ sich vieles durch Produktionslogik organisieren. Teams mussten priorisieren, weil sie nicht alles gleichzeitig bauen konnten. Feedback kam langsamer. Schleifen waren teurer. Ein Teil der Qualitätslogik war dadurch in die Knappheit eingebaut.
Jetzt fällt diese Begrenzung teilweise weg.
AI macht es billiger,
- Varianten zu erzeugen
- Analysen zusammenzufassen
- Entwürfe zu produzieren
- Code, Text, Bilder oder Reports in Menge zu liefern
Das klingt zunächst wie ein reines Produktivitätsgeschenk. Ist es auch. Nur verschiebt sich damit der Engpass.
Wenn fünfmal mehr produziert werden kann, wächst nicht automatisch mit,
- wer das prüft
- wer zwischen brauchbar und gefährlich unterscheidet
- wer erkennt, dass das Ergebnis zwar formal okay, aber strategisch daneben ist
- wer die Zielkonflikte sauber hält
Dann entstehen drei typische Muster.
1. Mehr Output, gleiche Urteilskapazität
Das Ergebnis ist Stau. Entweder wird später freigegeben, oder oberflächlicher. Beides sieht im Reporting zunächst nicht dramatisch aus. Aber Qualität kippt dann entweder in Verzögerung oder in Flüchtigkeit.
2. Bewertung wird schematisiert
Um mit der Masse klarzukommen, werden Prüfschritte stärker formalisiert. Checklisten, Standards, Gates, Scorecards. Das kann sinnvoll sein. Es wird gefährlich, wenn die Organisation den Unterschied zwischen schnellerer Prüfung und echtem Urteil vergisst.
Denn Checklisten sind nützlich für wiederkehrende Fehler. Sie ersetzen nicht die Fähigkeit, einen neuen Fehler als neuen Fehler zu erkennen.
3. Bewertung wird unsichtbar ausgelagert
Dann entstehen implizite Judge-Rollen. Einzelne Seniors, einzelne Leads, einzelne Domänenköpfe tragen die letzte Bewertungsarbeit, aber ohne dass ihre Kriterien wirklich sichtbar, dokumentiert oder skalierbar wären. Die Firma glaubt dann, sie habe Evaluationslogik. In Wahrheit hat sie Menschen, die still die Löcher stopfen.
Das kann eine Weile gutgehen. Es ist aber keine belastbare Architektur.
Goodhart arbeitet schneller als das Board
Charles Goodhart hat den berühmten Satz geprägt, dass eine Metrik ihren Erkenntniswert verliert, sobald sie zum Ziel wird. Das klingt theoretisch. In AI-Organisationen ist es erstaunlich praktisch.
Sobald eine Kennzahl wichtig genug wird, beginnt die Organisation, auf sie zu reagieren. Nicht zwingend böswillig. Oft einfach rational.
Typische Fälle sieht man schon jetzt:
- hohe AI-Nutzung wird als Transformationsfortschritt gelesen
- gesparte Zeit wird als geschaffener Wert verbucht
- weniger Headcount wird als robusterer Betrieb verkauft
- schnellere Output-Produktion wird mit besserer Organisation verwechselt
Nichts davon ist automatisch falsch. Alles davon kann falsch werden, sobald es die eigentliche Frage ersetzt.
Dann wird aus Steuerung ein Selbstberuhigungssystem.
Eine hohe Adoptionsrate kann bedeuten, dass Teams AI sinnvoll in Arbeit integriert haben. Sie kann aber auch bedeuten, dass Leute das Tool oft öffnen, weil genau diese Nutzung nun sichtbar und erwünscht ist. Eine gesunkene Bearbeitungszeit kann Effizienz bedeuten. Sie kann aber auch heißen, dass still mehr Risiko nach vorne gezogen oder nach hinten verschoben wurde. Gesparte Stunden können echte Entlastung sein. Sie können aber genauso schnell in zusätzliche Meeting-Last oder höhere Taktung umgewandelt werden.
Viele Firmen bauen heute keine Lernsysteme. Sie bauen metrisch polierte Selbsttäuschung.
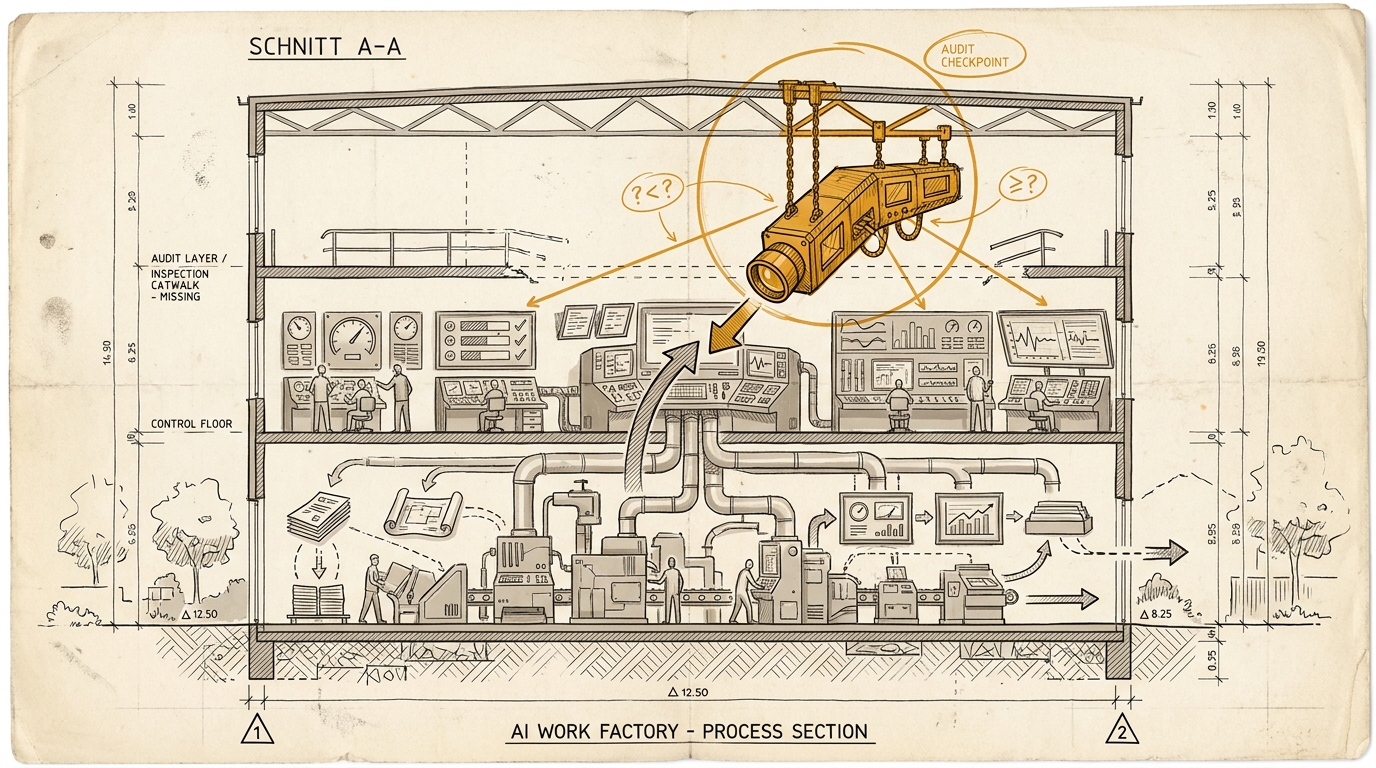
Die Auditschicht
Darum reicht es nicht, Operations und Control zu bauen. Es braucht jemanden oder etwas darüber, das nicht nur Ergebnisse prüft, sondern die Prüflogik selbst.
Operations produziert Arbeit. Control misst, verteilt und überwacht. Audit stellt die unangenehmere Frage: Sehen wir mit diesen Kennzahlen und Reviews die Realität überhaupt richtig?
Dort beginnen die harten Fragen:
- Warum glauben wir, dass diese Kennzahl etwas Relevantes misst?
- Wie könnte sie steigen, ohne dass echter Wert entsteht?
- Unter welchen Bedingungen kippt unser Review-Modell?
- Welche Fehlerart sehen wir systematisch zu spät?
- Wo liegt die Spur außerhalb des Systems selbst?
Spätestens an dieser Stelle ist Evaluation kein reines Technikthema mehr.
Denn die Auditschicht entscheidet nicht nur, wie geprüft wird. Sie entscheidet, welche Form von Wahrheit in der Organisation überhaupt zugelassen ist.
Warum das Führung ist und nicht nur Qualitätssicherung
Evaluation klingt harmlos, solange man an Qualitätskontrolle denkt. Ein Ergebnis ist gut oder schlecht. Ein Modell ist brauchbar oder nicht. Ein Testfall ist bestanden oder nicht.
In Unternehmen entscheidet Evaluation aber über mehr. Sie legt fest,
- welche Arbeit als gut gilt
- welche Risiken sichtbar werden
- welche Fehler tolerierbar sind
- welcher Kompromiss zwischen Tempo und Genauigkeit akzeptiert wird
- welche Form von Urteil aufgebaut oder verdrängt wird
Und genau deshalb ist das Führungsarbeit.
Denn hier entscheidet sich, worauf die Organisation überhaupt lernt.
Wenn das Zielsystem schlecht gebaut ist, lernt die Firma das Falsche schneller. Wenn die Prüflogik nur Berichtsfähigkeit belohnt, wächst Berichtsfähigkeit. Wenn Review-Kapazität unterschätzt wird, wächst Produktion in eine Freigabelücke hinein. Wenn lokale Kennzahlen über Systemwirkung siegen, produziert die Organisation saubere Einzelerfolge mit schlechtem Gesamteffekt.
Evaluation ist also nicht der Schlussakkord nach der Arbeit. Sie ist der Mechanismus, der bestimmt, welche Arbeit sich künftig wiederholt.
Die deutsche Chance liegt nicht in mehr Bürokratie
Der DACH-Blickwinkel ist hier entscheidend, weil er leicht missverstanden wird.
Deutsche Governance wirkt oft wie Reibung. Betriebsrat, Datenschutz, interne Revision, Dokumentationspflichten, Freigaben. Wer AI nur als Produktivitätstool liest, sieht darin vor allem Bremse. Und ja: Die gibt es auch. Vor allem dann, wenn man diese Ebenen falsch benutzt.
Dann greift man zu kurz.
Sobald Execution billiger wird, steigt der Wert sauberer Evaluation. Dann werden genau die Dinge interessant, die vorher wie lästige Kontrolle wirkten:
- eine Auditierbarkeit außerhalb des Systems
- dokumentierbare Freigaben
- nachvollziehbare Bewertungslogik
- institutionalisierter Zweifel an schönen Dashboards
Natürlich kann das auch in Bürokratie kippen. Das ist kein Automatismus zum Guten. Beileibe nicht. Aber es ist ein echter Vorteil gegenüber einem reinen Speed-Narrativ, in dem Kontrolle zwar skaliert, aber die Prüflogik selbst nie ernsthaft überprüft wird. Bedenken second ist keine gesunde Art, Führung zu leben.
Mitbestimmung erzwingt hier oft die besseren Fragen als so manche Wachstumsfolie.
Wenn Arbeit beschleunigt, verdichtet oder algorithmisch anders bewertet wird, reicht kein hübsches KPI-Deck. Dann muss erklärt werden,
- was eigentlich gemessen wird
- woran Qualität hängt
- welche Risiken sichtbar sein sollen
- wo menschliches Urteil unverzichtbar bleibt
Das ist anstrengend. Aber es ist näher an Wahrheit.
Wer darf bei euch die Kennzahl selbst angreifen?
Das ist die Führungsfrage dieses Textes.
- Nicht: Welche Metriken habt ihr?
- Nicht: Welche Tools nutzt ihr?
- Nicht: Welche Freigabeprozesse existieren?
Sondern: Wer in eurer Organisation darf die Prüflogik selbst in Frage stellen, ohne sofort als Bremser zu gelten?
Wer darf sagen, dass die grüne Kennzahl vielleicht nur Aktivität misst? Wer darf darauf hinweisen, dass mehr Output bei gleicher Review-Kapazität kein Effizienzgewinn, sondern ein Qualitätsrisiko ist?
Wenn niemand diese Rolle institutionalisiert hat, fehlt euch nicht einfach ein weiteres Tool. Dann fehlt euch die Auditschicht.
Und genau dort beginnt die neue Führungsarbeit: bei der Frage, ob euer eigener Steuerungsapparat noch zwischen Aktivität und Wahrheit unterscheiden kann.
Praktischer Test zum Essay
Drei Vorlagen für ein Gespräch mit einer KI: Ziel klären, Widersprüche prüfen, Delegierbarkeit testen. Du bekommst keine fertige Strategie und keine Tool-Empfehlung.
Vorlagen öffnenTiefer einsteigen
Drei Anschlussstücke, wenn du den Gedanken vertiefen willst.
Das falsche Black-Box-Problem
Nicht das Modell ist oft das größte Rätsel, sondern das Unternehmen selbst: Regeln fehlen, Wissen steckt in Köpfen, Entscheidungen werden offiziell …
Wer baut eure Urteilskraft?
Viele Unternehmen führen AI als Produktivitätshebel ein. Dabei automatisieren sie oft genau die Arbeitsschichten, auf denen später Qualität und …
Was wollt ihr eigentlich?
Viele Unternehmen behandeln AI als Toolfrage. Häufig können sie nicht einmal sauber sagen, was sie eigentlich wollen.